N糖基化是蛋白质常见的翻译后修饰,具有高度复杂的结构[1],在细胞黏附、免疫调控等生物过程中扮演关键角色[2],其失调与自身免疫病[3]、癌症等重大疾病密切相关[4]。然而,完整N糖基化分析始终面临下列核心矛盾:
1. 临床珍贵样本的稀缺性与糖肽分析对样本量的刚性需求之间的矛盾;
2. 大规模队列研究对高通量数据的迫切需求与完整糖型解析高度复杂的计算逻辑之间的矛盾;
3. 机制研究对低丰度糖型挖掘的深度需求与传统单次富集策略鉴定“天花板”之间的矛盾。
传统的解决方案往往迫使研究者在样本投入量、分析通量与鉴定深度之间做出艰难妥协,目前完整N糖基化分析的样本量下限通常为30 mg组织或5×106个细胞。
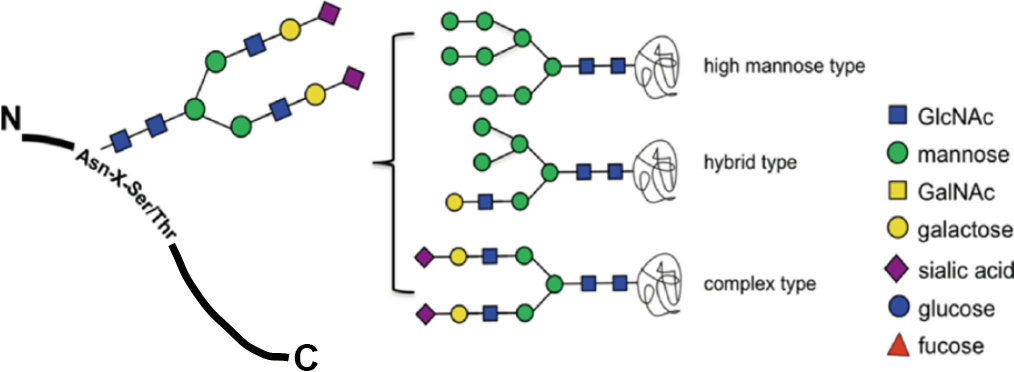
图1 蛋白质N糖基化的模式序列和基本结构
基于上述科学挑战,我们构建了一套面向不同研究场景的分层式完整N糖基化分析平台:N糖基化标准版和N糖基化高级版。其核心创新在于:在保持前端富集材料与后端计算引擎统一性的基础上,通过样本前处理策略的差异化设计,实现对“稳健分析”与“深度挖掘”两大场景的精准适配。
01 产品特色
微量样本|完整糖肽鉴定|快速高通量分析|鉴定覆盖度深
☆ 亮点一:酰胺HILIC材料——高效富集,微量样本的“捕获器”
亲水作用色谱(HILIC):无歧视性富集完整糖肽的标准策略,电中性的酰胺基键合相更能提升对含有唾液酸、磷酸甘露糖、氨基葡萄糖等特殊低丰度糖基化修饰的富集收率[5]。
优势:对完整糖肽具有优异的保留能力,尤其适合微量起始样本。结果:在低至30微克的全蛋白起始量(对应0.2~0.3mg组织)下仍能实现约2000条完整N糖肽的高效富集,为稀缺样本的深度糖基化分析铺平道路。
☆ 亮点二:完整糖肽的原位修饰鉴定——一次实验,多维解析
本平台聚焦于完整糖肽原位(in situ)结构的定量解析,以克服传统方法仅采集糖基化位点或糖链组成信息的不足。
一次LC-MS分析同时获得:
👉蛋白质的高置信度糖基化位点
👉修饰位点原位上的完整N糖链结构与组成
👉各个位点特异性糖型的无标定量丰度
应用价值:为疾病标志物筛选、药物糖基化异质性分析、糖生物学机制研究提供更可靠的分子依据。

图2 完整糖肽原位鉴定得到的蛋白质糖基化修饰信息
☆ 亮点三:改进的LC-MS分析方法——耗时更短,信息更全
本平台对LC和MS设置进行全面优化,高效解决传统分析方法的痛点:
👉液相色谱梯度缩短50%以上,节省宝贵的分析时间
👉调适MS碰撞能量模式和数值,兼顾肽段和不同结构糖链的碎片产生,提升完整糖肽离子化效率[6]
👉提高谱图采集分辨率并优化强度阈值、离子注入时间等参数,精确区分相近分子量的糖链结构,提升低丰度N糖肽的鉴定覆盖度
技术意义:为大队列样本采集、发掘稀有糖基化修饰、糖基化微观异质性分析提供精准的手段
☆ 亮点四:基于 pGlyco 3.1 软件的高通量、模块化、可追溯的数据分析
修饰信息全覆盖:该软件整合多种内置工具,一键完成从质谱原始数据到确定蛋白质N糖基化位点和糖链结构的全流程;
谱图可视化:gLabel工具支持完整糖肽MS2谱图的肽段序列和糖链结构注释,保障数据的可追溯性;
完整糖型解析:支持位点特异性(site-specific)与聚糖结构级(structural-level)的糖肽鉴定,避免混淆分子量相近的糖肽序列和糖基化修饰[7]。
结果:数据产出高效、可追溯,告别“黑箱”操作,重现性有保障。
☆ 亮点五:对高通量与微量样本的广泛兼容性
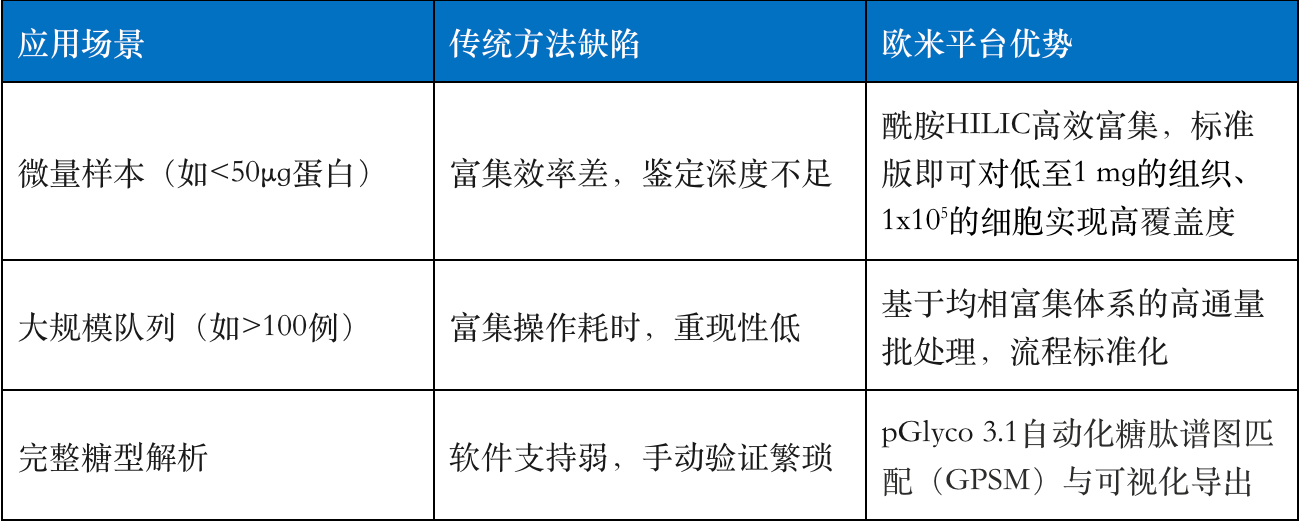
表1 N糖基化蛋白质组学技术升级:传统方法痛点 vs 欧米平台优势
02 技术路线
西湖欧米N糖基化蛋白质组学流程
👉步骤1:样本前处理与蛋白的酶解
采用优化的蛋白提取规程,确保覆盖到细胞和组织的全部蛋白
精准控制酶解条件,避免糖肽降解和蛋白酶自解的干扰,提升糖肽得率
👉步骤2:完整糖肽富集(酰胺HILIC)
利用亲水作用色谱原理,通过酰胺基键合相的氢键等非共价作用,特异性结合完整N糖肽的糖链
优化洗涤与洗脱条件,最大程度排除高丰度的非糖肽干扰,并尽量保留完整糖肽
👉步骤3:分馏策略(高级版专属)
基于糖肽的肽段序列亲水性、糖链结构等理化性质进行HPLC预分级
将富集后的糖肽样本分成多个组分以提升样本正交性,分别进行质谱分析
科学逻辑:降低单次进样的样本复杂度,并将低丰度糖肽物质的量提升到质谱检出限以上
👉步骤4:LC-MS/MS检测
采用Thermo公司Orbitrap Exploris 480高分辨质谱仪,配合优化后的LC梯度与糖肽HCD碎裂参数
以氧鎓离子等糖肽特征性碎片作为数据依赖性(DDA)采集的触发信号
👉步骤5:pGlyco 3.1数据解析
整合多种软件工具进行快速、灵敏的糖肽搜库
一次性确定蛋白质的N糖基化位点和糖链结构,并完成糖肽的FDR质控
基于gLabel的糖肽谱图匹配(glycopeptide spectrum match, GPSM)可视化验证和导出
👉步骤6:生物信息学分析
位点特异性糖型的定性和定量统计
糖型结构组成分析(岩藻糖、唾液酸、磷酸甘露糖等特征糖基)
差异糖型筛选与功能富集分析

03 实测数据
西湖欧米N糖基化蛋白质组学实测
标准版实测数据👇
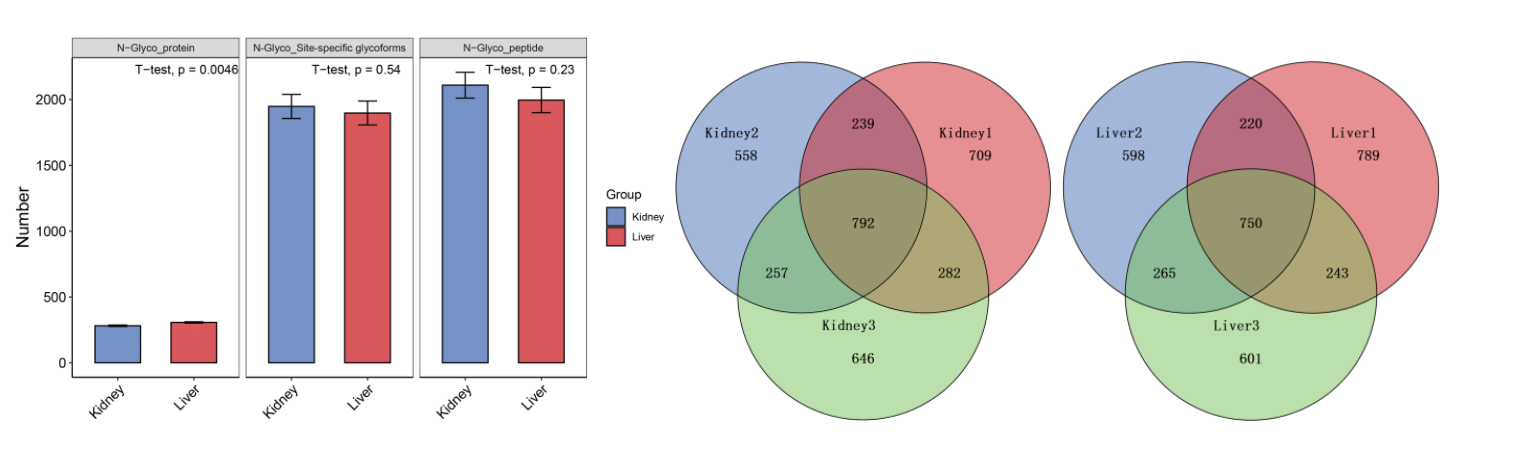
图3 来自3只小鼠的肾脏、肝脏组织的N糖蛋白、糖基化位点和完整糖肽数据
鉴定深度:从小鼠肾脏、肝脏的30~50 μg起始蛋白中鉴定完整N糖肽数量稳定在1800~2000条,覆盖100~200种糖链结构;
分析通量:单批次可处理超过10例样本,LC梯度耗时减少50~60%;
重现性:每两个生物学重复样本,鉴定完整糖肽的重叠率都达到60%。
高级版实测数据👇
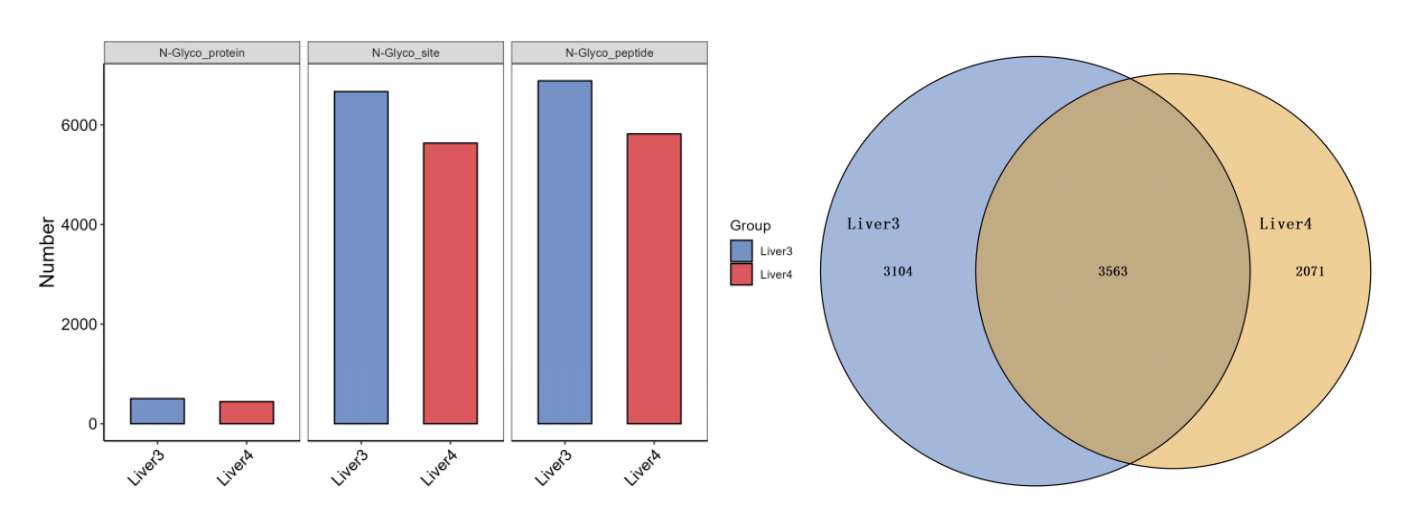
图4 来自2只小鼠的肝脏组织的N糖蛋白、糖基化位点和完整糖肽数据
分馏性能(高级版专属流程):从小鼠肝脏的250μg起始蛋白鉴定完整N糖肽数量达到6400±500条,覆盖约450种糖链结构
04 产品概述
双版本体系——从“稳健”到“极致”的精准适配
♦ 糖基化标准版——常量样本 + 珍贵样本的高通量稳健分析
定位:面向常规样本量及临床珍贵样本,在保证样本利用率的前提下,实现高通量、高重现性的完整N糖基化分析。
适用场景:
◊大规模临床队列样本(血清、血浆、尿液等)
◊珍贵稀缺样本(穿刺组织、流式分选细胞、FFPE样本)
◊药物糖型异质性的常规质控
技术特征:
◊样本前处理:采用优化的单次酰胺HILIC富集流程,确保富集效率与回收率的稳定性
◊数据产出:基于标准化流程实现高通量批处理(每批>10份样本),提高大样本队列数据的一致性
◊性能指标:在常量样本投料下,实现深度覆盖的完整糖肽鉴定,满足多数生物学研究的糖型分析需求
核心优势:在保证数据质量与重现性的前提下,将研究者从繁琐的样本处理与数据分析中解放出来,实现“高通量·高稳健·高性价比”的糖基化分析。
♦ 糖基化高级版——分馏策略驱动,鉴定量提升3倍
定位:面向追求极致鉴定深度的研究场景,通过分馏(fractionation)前处理策略,突破传统单次富集的糖肽鉴定“天花板”。
适用场景:
◊稀缺样本的深度糖型图谱绘制
◊低丰度糖型/稀有糖结构的发掘与验证
◊机制研究中需要完整糖型覆盖最大化的场景
技术特征:
◊核心创新:引入分馏策略,将酰胺HILIC富集后的完整糖肽样本按亲水性、电荷、糖链结构等理化性质进行分级分离
◊科学逻辑:分馏有效降低了单次质谱进样中糖肽的复杂度,使质谱仪能够更高效地检测到低丰度糖肽信号,从而显著提升糖肽鉴定深度
◊性能指标:完整糖肽鉴定数量较标准版单次富集策略提升近3倍,且覆盖糖链结构显著增加[8]
核心优势:以分馏策略为技术支点,实现从“常规覆盖”到“极致深度”的质变,为稀缺样本的糖生物学机制研究提供更完整的数据支撑。
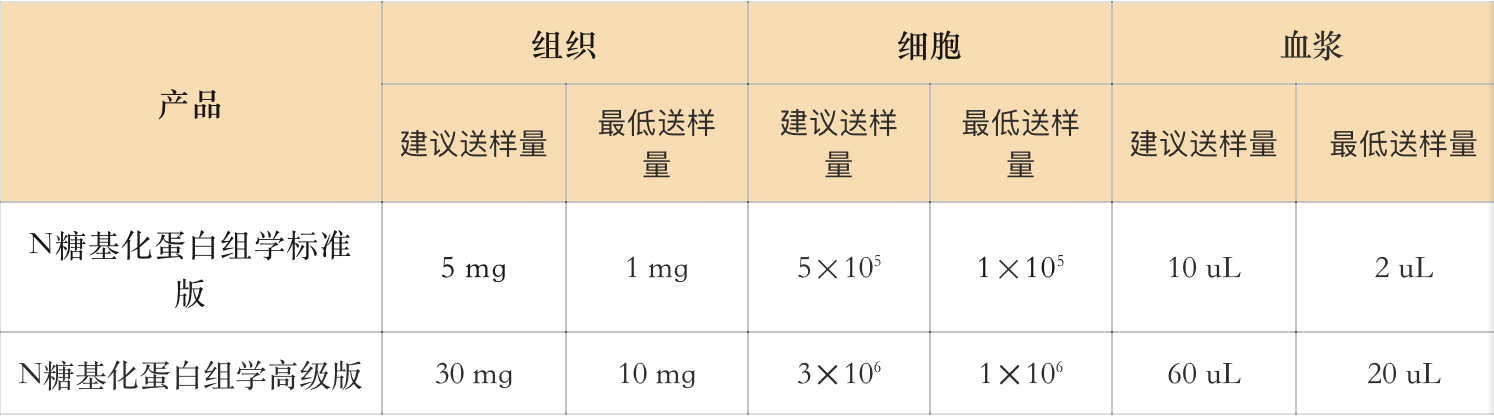
送样建议
表2 N糖基化蛋白质组学送样建议
完整N糖基化分析正从“能测”走向“测深、测准、测快”,西湖欧米特推出基于酰胺HILIC富集 + pGlyco 3.1分析的完整N糖基化分析平台,专为微量样本和高通量场景打造,助力您的糖蛋白组学研究迈上新台阶。
参考文献:
[1] Thaysen-Andersen M, Packer N H and Schulz B L. Maturing glycoproteomics technologies provide unique structural insights into the N-glycoproteome and its regulation in health and disease. Molecular & Cellular Proteomics, 2016, 15(6): 1773–1790.
[2] Ohtsubo K and Marth J D. Glycosylation in cellular mechanisms of health and disease. Cell, 2006, 126(5): 855–867.
[3] Lowe J B. Glycosylation, immunity, and autoimmunity. Cell, 2001, 104(6): 809–812.
[4] Pinho S S, Reis C A. Glycosylation in cancer: mechanisms and clinical implications. Nature Reviews Cancer, 2015, 15(9): 540–555.
[5] Qing G, Yan J, He X, et al. Recent advances in hydrophilic interaction liquid interaction chromatography materials for glycopeptide enrichment and glycan separation. Trends in Analytical Chemistry, 2020, 124: 115570.
[6] Qin H, Chen Y, Mao J, et al. Proteomics analysis of site-specific glycoforms by a virtual multistage mass spectrometry method. Analytica Chimica Acta, 2019, 1070: 60–68.
[7] Liu M-Q, Zeng W-F, Fang P, et al. pGlyco 2.0 enables precision N-glycoproteomics with
comprehensive quality control and one-step mass spectrometry for intact glycopeptide identification. Nature Communications, 2017, 8:438.
[8] Chen Y, Fang Z, Zhou J, et al. Mirror-cutting-based digestion strategy enables the in-depth and accuracy characterization of N-linked protein glycosylation [J]. Journal of Proteome Research, 2021, 20(11): 4948–4958.
如果您正面临以下问题,欢迎在【西湖欧米】公众号评论区留言或私信我们
提问1:您的样本类型与可用起始量?
A. 细胞(___细胞量)
B. 组织(___mg原始组织)
C. 其他()
提问2:您的研究目标更侧重?
A. 大规模队列标志物筛选 → 推荐标准版
B. 稀缺样本深度糖型图谱 → 推荐高级版
C. 药物糖型异质性分析
D. 机制探索与功能研究
提问3:您在完整N糖基化修饰分析中遇到的最大瓶颈是?
A. 样本量不足,富集效率低
B. 数据通量低,处理耗时长
C. 糖型覆盖率不够,低丰度糖型测不到
D. 生信分析复杂,不知如何深入挖掘
✨我们将为前10位留言的用户提供双版本定制化方案咨询,欢迎留言并私信✨
N糖基化是蛋白质常见的翻译后修饰,具有高度复杂的结构[1],在细胞黏附、免疫调控等生物过程中扮演关键角色[2],其失调与自身免疫病[3]、癌症等重大疾病密切相关[4]。然而,完整N糖基化分析始终面临下列核心矛盾:
1. 临床珍贵样本的稀缺性与糖肽分析对样本量的刚性需求之间的矛盾;
2. 大规模队列研究对高通量数据的迫切需求与完整糖型解析高度复杂的计算逻辑之间的矛盾;
3. 机制研究对低丰度糖型挖掘的深度需求与传统单次富集策略鉴定“天花板”之间的矛盾。
传统的解决方案往往迫使研究者在样本投入量、分析通量与鉴定深度之间做出艰难妥协,目前完整N糖基化分析的样本量下限通常为30 mg组织或5×106个细胞。
图1 蛋白质N糖基化的模式序列和基本结构
基于上述科学挑战,我们构建了一套面向不同研究场景的分层式完整N糖基化分析平台:N糖基化标准版和N糖基化高级版。其核心创新在于:在保持前端富集材料与后端计算引擎统一性的基础上,通过样本前处理策略的差异化设计,实现对“稳健分析”与“深度挖掘”两大场景的精准适配。
01 产品特色
微量样本|完整糖肽鉴定|快速高通量分析|鉴定覆盖度深
☆ 亮点一:酰胺HILIC材料——高效富集,微量样本的“捕获器”
亲水作用色谱(HILIC):无歧视性富集完整糖肽的标准策略,电中性的酰胺基键合相更能提升对含有唾液酸、磷酸甘露糖、氨基葡萄糖等特殊低丰度糖基化修饰的富集收率[5]。
优势:对完整糖肽具有优异的保留能力,尤其适合微量起始样本。结果:在低至30微克的全蛋白起始量(对应0.2~0.3mg组织)下仍能实现约2000条完整N糖肽的高效富集,为稀缺样本的深度糖基化分析铺平道路。
☆ 亮点二:完整糖肽的原位修饰鉴定——一次实验,多维解析
本平台聚焦于完整糖肽原位(in situ)结构的定量解析,以克服传统方法仅采集糖基化位点或糖链组成信息的不足。
一次LC-MS分析同时获得:
👉蛋白质的高置信度糖基化位点
👉修饰位点原位上的完整N糖链结构与组成
👉各个位点特异性糖型的无标定量丰度
应用价值:为疾病标志物筛选、药物糖基化异质性分析、糖生物学机制研究提供更可靠的分子依据。
图2 完整糖肽原位鉴定得到的蛋白质糖基化修饰信息
☆ 亮点三:改进的LC-MS分析方法——耗时更短,信息更全
本平台对LC和MS设置进行全面优化,高效解决传统分析方法的痛点:
👉液相色谱梯度缩短50%以上,节省宝贵的分析时间
👉调适MS碰撞能量模式和数值,兼顾肽段和不同结构糖链的碎片产生,提升完整糖肽离子化效率[6]
👉提高谱图采集分辨率并优化强度阈值、离子注入时间等参数,精确区分相近分子量的糖链结构,提升低丰度N糖肽的鉴定覆盖度
技术意义:为大队列样本采集、发掘稀有糖基化修饰、糖基化微观异质性分析提供精准的手段
☆ 亮点四:基于 pGlyco 3.1 软件的高通量、模块化、可追溯的数据分析
修饰信息全覆盖:该软件整合多种内置工具,一键完成从质谱原始数据到确定蛋白质N糖基化位点和糖链结构的全流程;
谱图可视化:gLabel工具支持完整糖肽MS2谱图的肽段序列和糖链结构注释,保障数据的可追溯性;
完整糖型解析:支持位点特异性(site-specific)与聚糖结构级(structural-level)的糖肽鉴定,避免混淆分子量相近的糖肽序列和糖基化修饰[7]。
结果:数据产出高效、可追溯,告别“黑箱”操作,重现性有保障。
☆ 亮点五:对高通量与微量样本的广泛兼容性
表1 N糖基化蛋白质组学技术升级:传统方法痛点 vs 欧米平台优势
02 技术路线
西湖欧米N糖基化蛋白质组学流程
👉步骤1:样本前处理与蛋白的酶解
采用优化的蛋白提取规程,确保覆盖到细胞和组织的全部蛋白
精准控制酶解条件,避免糖肽降解和蛋白酶自解的干扰,提升糖肽得率
👉步骤2:完整糖肽富集(酰胺HILIC)
利用亲水作用色谱原理,通过酰胺基键合相的氢键等非共价作用,特异性结合完整N糖肽的糖链
优化洗涤与洗脱条件,最大程度排除高丰度的非糖肽干扰,并尽量保留完整糖肽
👉步骤3:分馏策略(高级版专属)
基于糖肽的肽段序列亲水性、糖链结构等理化性质进行HPLC预分级
将富集后的糖肽样本分成多个组分以提升样本正交性,分别进行质谱分析
科学逻辑:降低单次进样的样本复杂度,并将低丰度糖肽物质的量提升到质谱检出限以上
👉步骤4:LC-MS/MS检测
采用Thermo公司Orbitrap Exploris 480高分辨质谱仪,配合优化后的LC梯度与糖肽HCD碎裂参数
以氧鎓离子等糖肽特征性碎片作为数据依赖性(DDA)采集的触发信号
👉步骤5:pGlyco 3.1数据解析
整合多种软件工具进行快速、灵敏的糖肽搜库
一次性确定蛋白质的N糖基化位点和糖链结构,并完成糖肽的FDR质控
基于gLabel的糖肽谱图匹配(glycopeptide spectrum match, GPSM)可视化验证和导出
👉步骤6:生物信息学分析
位点特异性糖型的定性和定量统计
糖型结构组成分析(岩藻糖、唾液酸、磷酸甘露糖等特征糖基)
差异糖型筛选与功能富集分析
03 实测数据
西湖欧米N糖基化蛋白质组学实测
标准版实测数据👇
图3 来自3只小鼠的肾脏、肝脏组织的N糖蛋白、糖基化位点和完整糖肽数据
鉴定深度:从小鼠肾脏、肝脏的30~50 μg起始蛋白中鉴定完整N糖肽数量稳定在1800~2000条,覆盖100~200种糖链结构;
分析通量:单批次可处理超过10例样本,LC梯度耗时减少50~60%;
重现性:每两个生物学重复样本,鉴定完整糖肽的重叠率都达到60%。
高级版实测数据👇
图4 来自2只小鼠的肝脏组织的N糖蛋白、糖基化位点和完整糖肽数据
分馏性能(高级版专属流程):从小鼠肝脏的250μg起始蛋白鉴定完整N糖肽数量达到6400±500条,覆盖约450种糖链结构
04 产品概述
双版本体系——从“稳健”到“极致”的精准适配
♦ 糖基化标准版——常量样本 + 珍贵样本的高通量稳健分析
定位:面向常规样本量及临床珍贵样本,在保证样本利用率的前提下,实现高通量、高重现性的完整N糖基化分析。
适用场景:
◊大规模临床队列样本(血清、血浆、尿液等)
◊珍贵稀缺样本(穿刺组织、流式分选细胞、FFPE样本)
◊药物糖型异质性的常规质控
技术特征:
◊样本前处理:采用优化的单次酰胺HILIC富集流程,确保富集效率与回收率的稳定性
◊数据产出:基于标准化流程实现高通量批处理(每批>10份样本),提高大样本队列数据的一致性
◊性能指标:在常量样本投料下,实现深度覆盖的完整糖肽鉴定,满足多数生物学研究的糖型分析需求
核心优势:在保证数据质量与重现性的前提下,将研究者从繁琐的样本处理与数据分析中解放出来,实现“高通量·高稳健·高性价比”的糖基化分析。
♦ 糖基化高级版——分馏策略驱动,鉴定量提升3倍
定位:面向追求极致鉴定深度的研究场景,通过分馏(fractionation)前处理策略,突破传统单次富集的糖肽鉴定“天花板”。
适用场景:
◊稀缺样本的深度糖型图谱绘制
◊低丰度糖型/稀有糖结构的发掘与验证
◊机制研究中需要完整糖型覆盖最大化的场景
技术特征:
◊核心创新:引入分馏策略,将酰胺HILIC富集后的完整糖肽样本按亲水性、电荷、糖链结构等理化性质进行分级分离
◊科学逻辑:分馏有效降低了单次质谱进样中糖肽的复杂度,使质谱仪能够更高效地检测到低丰度糖肽信号,从而显著提升糖肽鉴定深度
◊性能指标:完整糖肽鉴定数量较标准版单次富集策略提升近3倍,且覆盖糖链结构显著增加[8]
核心优势:以分馏策略为技术支点,实现从“常规覆盖”到“极致深度”的质变,为稀缺样本的糖生物学机制研究提供更完整的数据支撑。
送样建议
表2 N糖基化蛋白质组学送样建议
完整N糖基化分析正从“能测”走向“测深、测准、测快”,西湖欧米特推出基于酰胺HILIC富集 + pGlyco 3.1分析的完整N糖基化分析平台,专为微量样本和高通量场景打造,助力您的糖蛋白组学研究迈上新台阶。
参考文献:
[1] Thaysen-Andersen M, Packer N H and Schulz B L. Maturing glycoproteomics technologies provide unique structural insights into the N-glycoproteome and its regulation in health and disease. Molecular & Cellular Proteomics, 2016, 15(6): 1773–1790.
[2] Ohtsubo K and Marth J D. Glycosylation in cellular mechanisms of health and disease. Cell, 2006, 126(5): 855–867.
[3] Lowe J B. Glycosylation, immunity, and autoimmunity. Cell, 2001, 104(6): 809–812.
[4] Pinho S S, Reis C A. Glycosylation in cancer: mechanisms and clinical implications. Nature Reviews Cancer, 2015, 15(9): 540–555.
[5] Qing G, Yan J, He X, et al. Recent advances in hydrophilic interaction liquid interaction chromatography materials for glycopeptide enrichment and glycan separation. Trends in Analytical Chemistry, 2020, 124: 115570.
[6] Qin H, Chen Y, Mao J, et al. Proteomics analysis of site-specific glycoforms by a virtual multistage mass spectrometry method. Analytica Chimica Acta, 2019, 1070: 60–68.
[7] Liu M-Q, Zeng W-F, Fang P, et al. pGlyco 2.0 enables precision N-glycoproteomics with
comprehensive quality control and one-step mass spectrometry for intact glycopeptide identification. Nature Communications, 2017, 8:438.
[8] Chen Y, Fang Z, Zhou J, et al. Mirror-cutting-based digestion strategy enables the in-depth and accuracy characterization of N-linked protein glycosylation [J]. Journal of Proteome Research, 2021, 20(11): 4948–4958.
如果您正面临以下问题,欢迎在【西湖欧米】公众号评论区留言或私信我们
提问1:您的样本类型与可用起始量?
A. 细胞(___细胞量)
B. 组织(___mg原始组织)
C. 其他()
提问2:您的研究目标更侧重?
A. 大规模队列标志物筛选 → 推荐标准版
B. 稀缺样本深度糖型图谱 → 推荐高级版
C. 药物糖型异质性分析
D. 机制探索与功能研究
提问3:您在完整N糖基化修饰分析中遇到的最大瓶颈是?
A. 样本量不足,富集效率低
B. 数据通量低,处理耗时长
C. 糖型覆盖率不够,低丰度糖型测不到
D. 生信分析复杂,不知如何深入挖掘
✨我们将为前10位留言的用户提供双版本定制化方案咨询,欢迎留言并私信✨