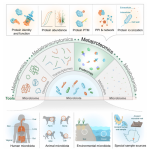
该研究与我们公司在AI和多模态大数据分析方面的业务方向高度契合,尤其在精准医学和药物研发领域具有重要的应用潜力。
1. 为什么需要虚拟细胞?

2. 当前进展与代表项目
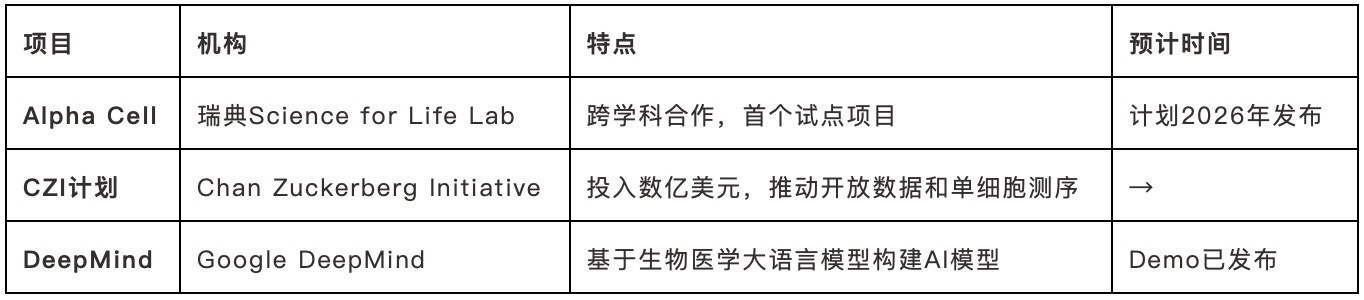
3. 方法路线比对
传统机制模型:例如2012年对Mycoplasma genitalium的全细胞建模,侧重生物物理和机制分析。

AI驱动的数据模型:当代的虚拟细胞项目依托于“基础模型”(foundation model),利用海量单细胞RNA测序数据训练AI模型。这与我们公司在多模态大数据分析中的应用非常契合,通过AI技术推动单细胞和蛋白质组数据的深度整合和建模。
4. 挑战与争议
仍处于初期阶段:虽然目标明确,但目前虚拟细胞系统尚未完善,实际应用仍处于早期阶段。 数据问题: 尽管单细胞RNA-seq数据量巨大,但缺乏足够的扰动(perturbation)数据,影响了模型的因果预测能力。
多模态数据整合的复杂性仍需解决,尤其是如何在不同数据源之间建立统一标准和评估体系。
5. 未来展望
多尺度生物实体的统一表示; 对扰动的可预测性和解释能力; 实验验证(Cycle-in-the-loop)模式的闭环训练。

免责声明:本篇文章由人工智能(ChatGPT 4o)撰写,内容基于相关文献、研究成果和现有科技进展的综合分析。虽然我们力求确保文章信息的准确性和可靠性,但由于AI生成内容的局限性,本文的观点和见解仅供参考。读者在应用或引用本文内容时,请自行核实相关信息和数据的有效性。我们不对任何因使用本文内容所导致的直接或间接损失承担责任。
该研究与我们公司在AI和多模态大数据分析方面的业务方向高度契合,尤其在精准医学和药物研发领域具有重要的应用潜力。
1. 为什么需要虚拟细胞?
2. 当前进展与代表项目
3. 方法路线比对
传统机制模型:例如2012年对Mycoplasma genitalium的全细胞建模,侧重生物物理和机制分析。
AI驱动的数据模型:当代的虚拟细胞项目依托于“基础模型”(foundation model),利用海量单细胞RNA测序数据训练AI模型。这与我们公司在多模态大数据分析中的应用非常契合,通过AI技术推动单细胞和蛋白质组数据的深度整合和建模。
4. 挑战与争议
仍处于初期阶段:虽然目标明确,但目前虚拟细胞系统尚未完善,实际应用仍处于早期阶段。 数据问题: 尽管单细胞RNA-seq数据量巨大,但缺乏足够的扰动(perturbation)数据,影响了模型的因果预测能力。
多模态数据整合的复杂性仍需解决,尤其是如何在不同数据源之间建立统一标准和评估体系。
5. 未来展望
多尺度生物实体的统一表示; 对扰动的可预测性和解释能力; 实验验证(Cycle-in-the-loop)模式的闭环训练。
免责声明:本篇文章由人工智能(ChatGPT 4o)撰写,内容基于相关文献、研究成果和现有科技进展的综合分析。虽然我们力求确保文章信息的准确性和可靠性,但由于AI生成内容的局限性,本文的观点和见解仅供参考。读者在应用或引用本文内容时,请自行核实相关信息和数据的有效性。我们不对任何因使用本文内容所导致的直接或间接损失承担责任。