






研究背景
肝细胞癌(HCC)是全球癌症相关死亡的主要原因之一,其早期诊断面临巨大挑战。目前临床常用的肿瘤标志物甲胎蛋白(AFP)灵敏度有限,难以满足早期筛查需求,因此迫切需要寻找高精度的非侵入性生物标志物。近年来研究发现蛋白质N-糖基化在肝脏疾病的发生发展过程中发挥关键调控作用,而血清N-糖基化谱的变化可能反映了肝脏的功能状态及恶性转化进程,为HCC的早期诊断提供了新的切入点。
2026年1月20日,复旦大学和广东省人民医院研究团队在Nature Communications上发表了题为 “Large-scale serum N-glycomics tracks N-glycosylation dynamics in hepatocellular carcinoma progression and enables early diagnosis” 的研究论文。本研究基于大队列样本系统解析了血清N-糖基化在HCC演进中的规律,既揭示了糖基化重编程的生物学机制,更开发出高精度诊断模型,为肝细胞癌的早期诊断和精准分型提供了新的解决方案。

文章标题
研究设计
队列样本:研究纳入1,074名中国受试者,覆盖健康对照(HC)、慢性乙型肝炎(CHB)、肝硬化(LC)和肝细胞癌(HCC)患者。
组学检测:高通量血清N-糖基化组学、位点特异性糖蛋白组学。
公共数据库资源:转录组学(TCGA/GEO数据分析)
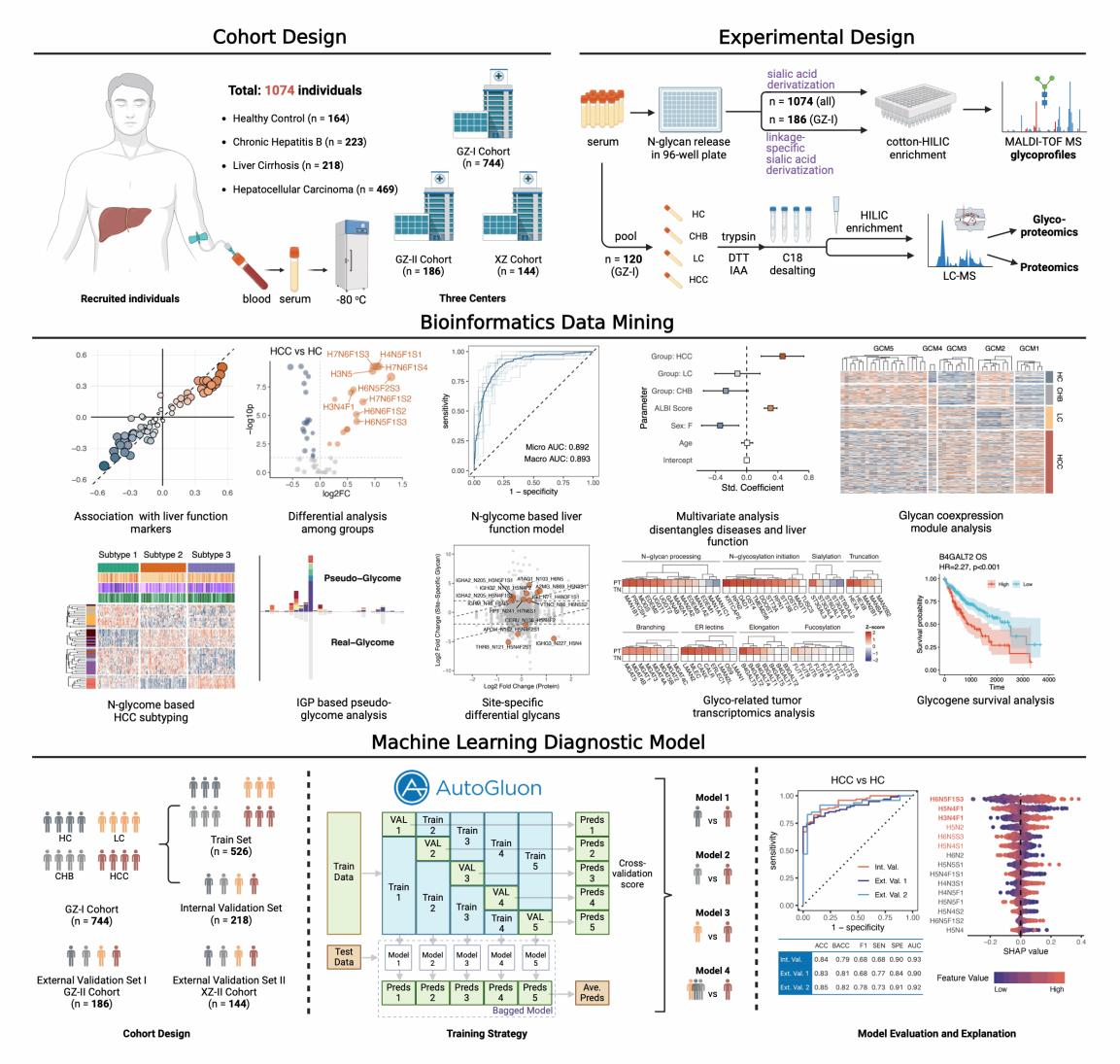
Fig. 1 研究概述
研究结果
01. 血清N-糖基化与肝功能恶化显著相关
本研究通过探讨血清N-糖组学特征与肝功能检查以及肝功能评分系统白蛋白-胆红素(ALBI)分期和Child-Pugh分级之间的关联(Fig.2a)。发现N-糖组学特征与肝功能检查及肝功能评分系统均呈现显著相关性(Fig.2b)。其中,肝功能较差的患者表现为分支化、GlcNAc双切和岩藻糖基化增加,同时伴有半乳糖基化和唾液酸化减少(Fig.2c)。同时,不同疾病亚组水平上的相关性模式与整体水平保持一致,其中肝硬化(LC)和肝癌(HCC)队列显示出显著的一致性(Fig.2e-f)。这表明蛋白质N-糖链可有效反映肝功能恶化,可作为评估肝功能的可靠标志物。
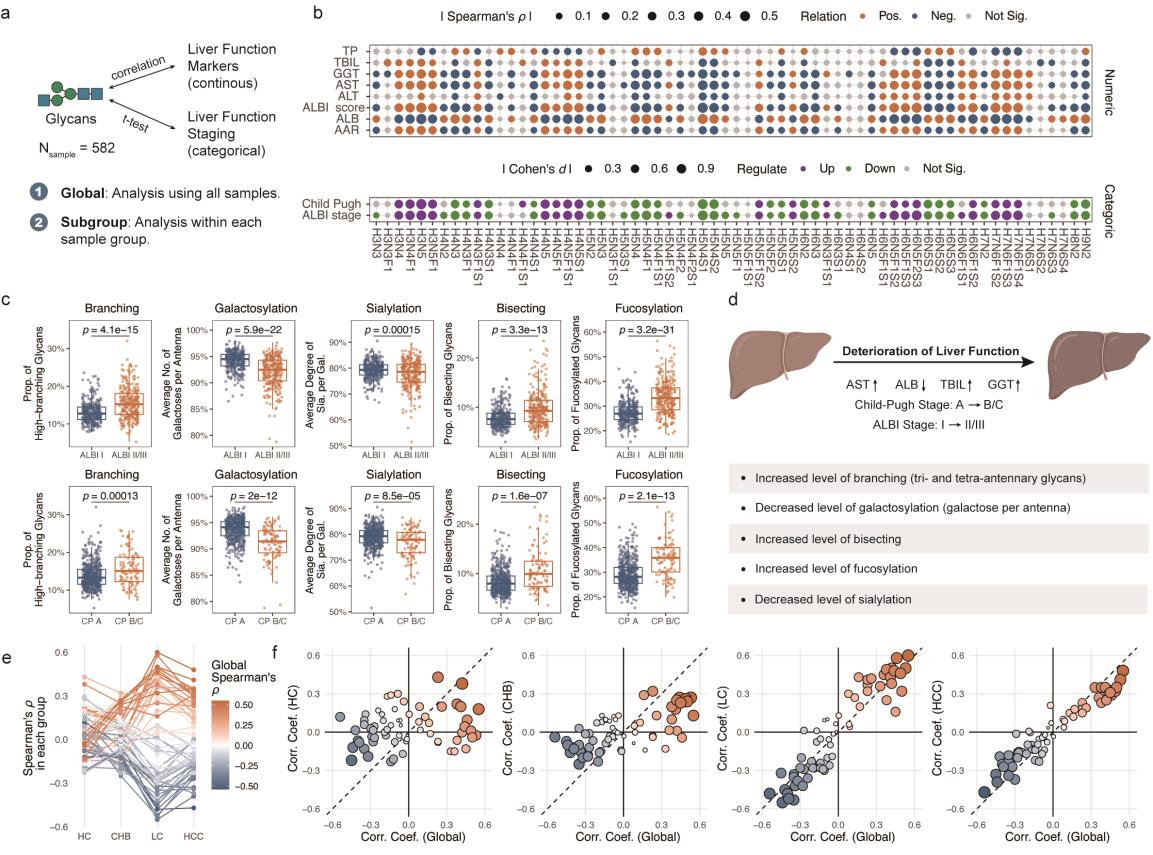
Fig. 2 血清N-糖组学与肝功能的相关性研究
02. HCC特异性糖基化特征重塑
对比分析发现,在不同疾病组间,HCC 血清N-糖基化修饰水平改变最为显著(Fig.3c),其次是肝硬化(Fig.3b)。而慢性肝炎中几乎未观察到显著的N-糖基化修饰变化(Fig.3a)。在肝硬化中,下调的N-糖链主要为三触角和四触角结构,且多唾液酸化,缺乏岩藻糖基化(Fig.3b)。而岩藻糖基化、多唾液酸化的三触角和四触角糖链在HCC 中特异性上调(Fig.3c-d)。根据表达模式分析,48种显著失调的N-糖链被划分为五个糖链共表达模块(GCMs)(Fig.3e)。每个GCM均呈现独特的表达谱(Fig.3f)和结构特征富集(Fig.3g),且表达相似性较低(Fig.3h)。同时,在各类肝脏疾病中均观察到血清N-糖组的特征性结构改变(Fig.3i)。
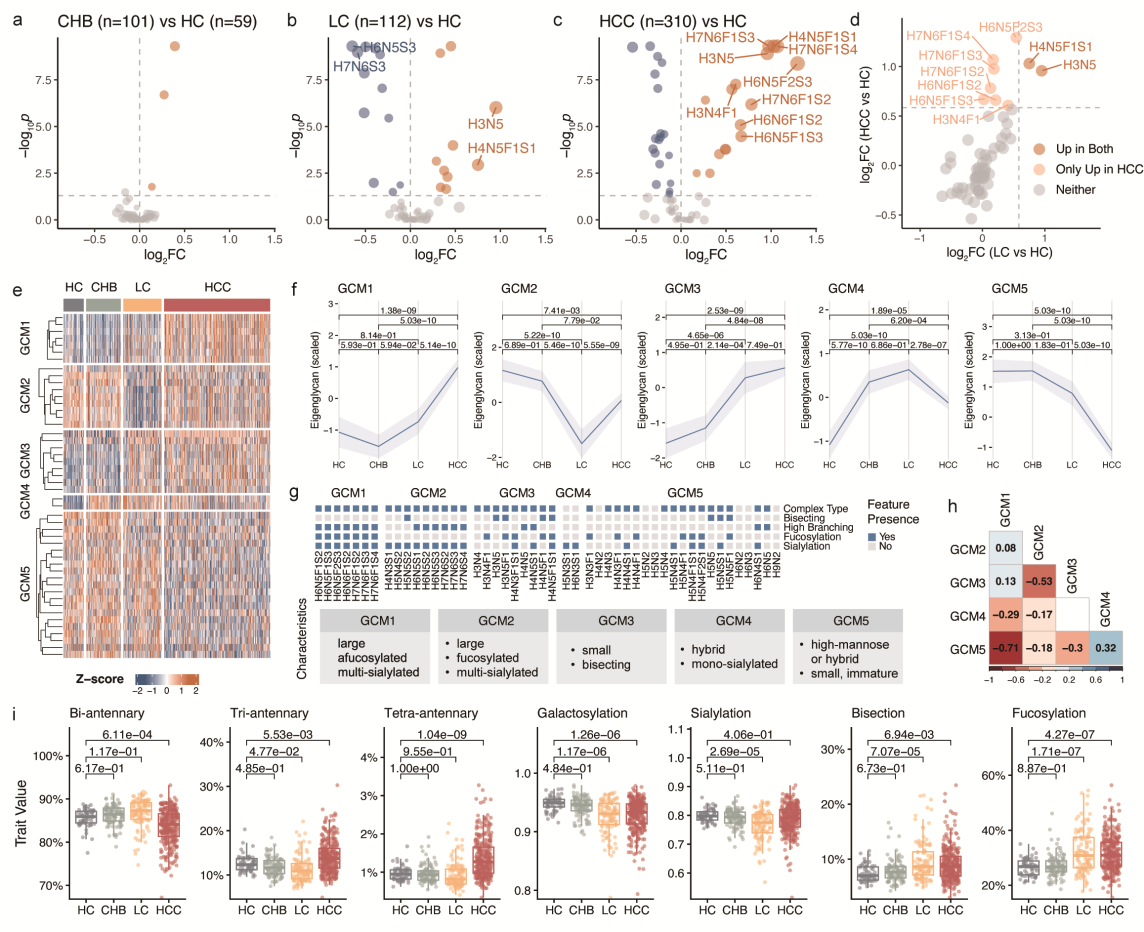
Fig. 3 血清N-糖组与肝脏疾病的相关性
03. 基于N-糖基化谱的HCC分子分型
研究进一步通过血清N-糖组数据的无监督共识聚类分析,将HCC 样本划分成了三个独特亚型(Fig.4a)。各亚型均呈现独特的N-糖链特征谱(Fig.4b)。亚型1的特征表现为GCM3中含双切N-乙酰葡糖胺(GlcNAc)的小型未成熟糖链水平升高,而GCM2中大型多唾液酸化、无岩藻糖基化糖链水平降低(Fig.4c,Fig.3g)。亚型2则表现为GCM1中大分子多唾液酸化、岩藻糖基化糖链水平下降。亚型3表现出GCM1糖链增加,同时GCM5中高甘露糖、杂合或小复合糖链水平降低,其糖组学特征与亚型1部分互补。此外,各亚型与临床参数(如肝功能,疾病分期)显著相关:亚型1、3的肝功能差于亚型2,且亚型2多处于疾病早期阶段。
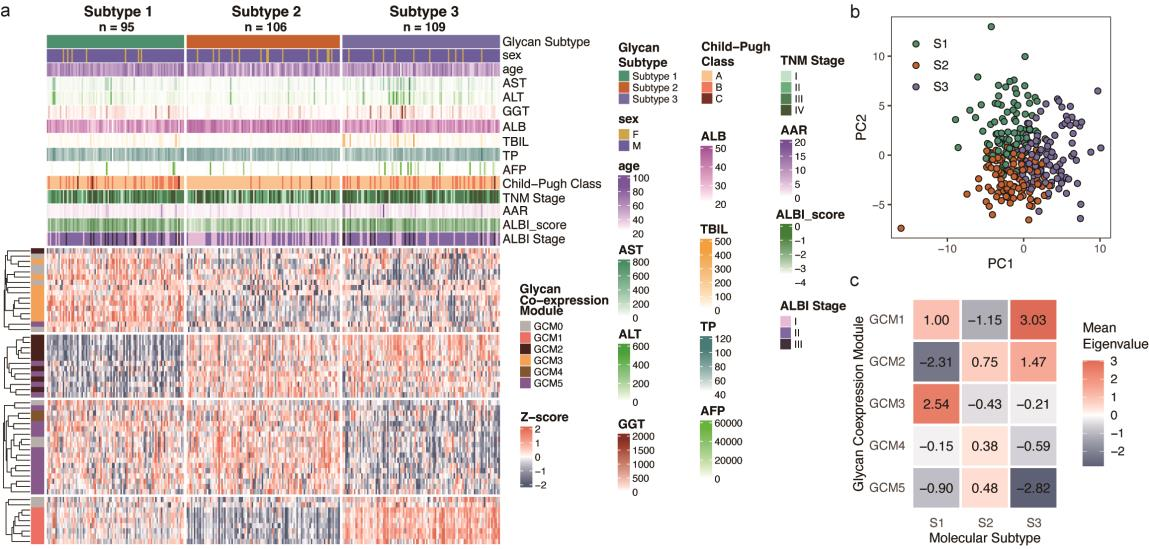
Fig. 4 基于N-糖基化谱的分子分型
04. 位点特异性糖基化分析
为进一步鉴定位点特异性糖基化,该研究采用DDA 精准模式对 GZ-I队列的一个子集(n=120,每组30例)进行正交N-糖蛋白质组学与蛋白质组学分析。共鉴定到 3,057 个糖肽、2,824 种位点特异性糖链、477 种糖链组成、276 个糖基化位点和 168 种糖蛋白。通过整合所有具有相同糖链组成的位点特异性糖链的定量数据,生成了伪糖组学谱。(Fig.5a)。这些伪糖组学谱与真实糖组学表现出高度一致性(平均Pearson相关系数r≈0.95),糖链显示出多样化的位点特异性贡献(Fig.5b-d)。而具有相似结构特征的糖链表现出相似的位点贡献(Fig.5d)。这些研究结果揭示了特异性位点对血清N-糖组中异质性的贡献,主要由一组高丰度糖蛋白驱动。
同时,研究人员选择那些在对应蛋白质丰度变化之外仍表现出显著改变的位点特异性糖链(SSGs)进行了差异分析(Fig.5e–g),并通过整合糖组学和糖蛋白组学数据,阐明了导致糖组改变的两种不同机制:糖基化主导机制和蛋白质主导机制。这为未来糖组学研究提供了重要启示:仅凭血清糖组数据可能不足以提供调控机制的深入见解。
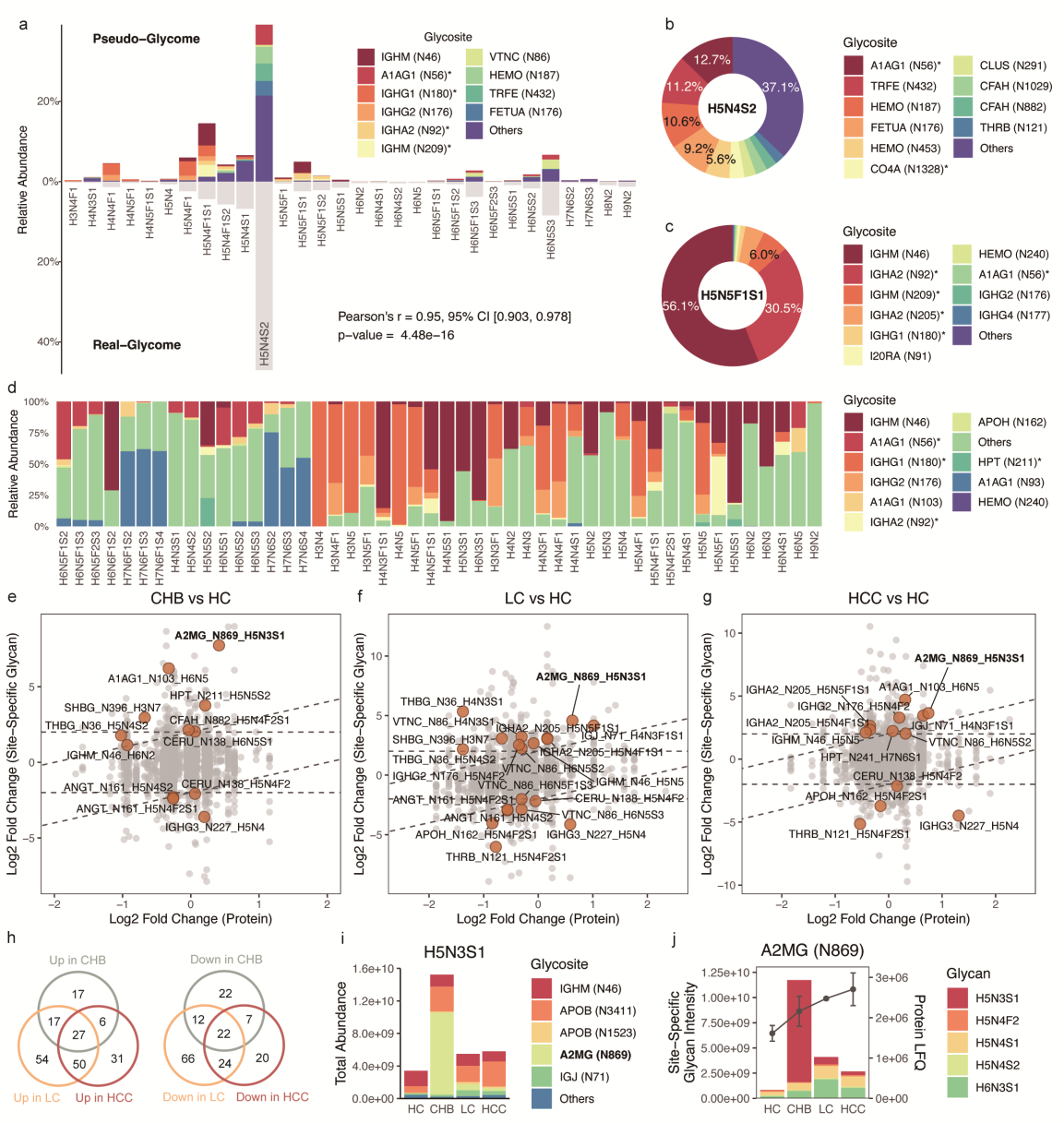
Fig. 5 糖基化修饰的位点特异性分析
05. 糖基化相关酶的转录调控
蛋白质N-糖基化是一个高度调控的过程,由多种糖基转移酶、糖苷酶及其他调控因子的有序作用所控制。为探究这些酶及调控因子的改变是否参与驱动 HCC 中观察到的N-糖基化变化,该研究分析了 TCGA - LIHC 数据集中的基因表达数据。在肝肿瘤组织中观察到糖基因的全局上调(Fig.6a)。差异表达分析(DEA)显示118个糖基因表达上调,仅有两个糖基因表达下调(Fig.6b),表明肿瘤细胞中N-糖基化整体增强。值得注意的是,催化N-糖链生物合成初始步骤、组装脂质连接寡糖前体、寡糖基转移酶复合体基因显著上调,表明 HCC 细胞不仅增强了初始糖基化生物合成,还提升了转移步骤效率,从而强化了N-糖基化整体格局。糖基因表达模式同时在7个GEO数据集中得到了验证(Fig.6c),表明在不同人群中存在高度保守的疾病相关糖基化失调。
最后,通过生存分析筛选具有预后价值的糖基因,半乳糖基转移酶成为关键预后指标:B4GALT2与总生存期显著相关(Fig.6d-e),而B4GALT3则与疾病进展密切相关(Fig.6f-g)。这些发现表明糖基化修饰可能在调控疾病进展和预后中发挥重要作用,为未来治疗干预提供了潜在靶点。
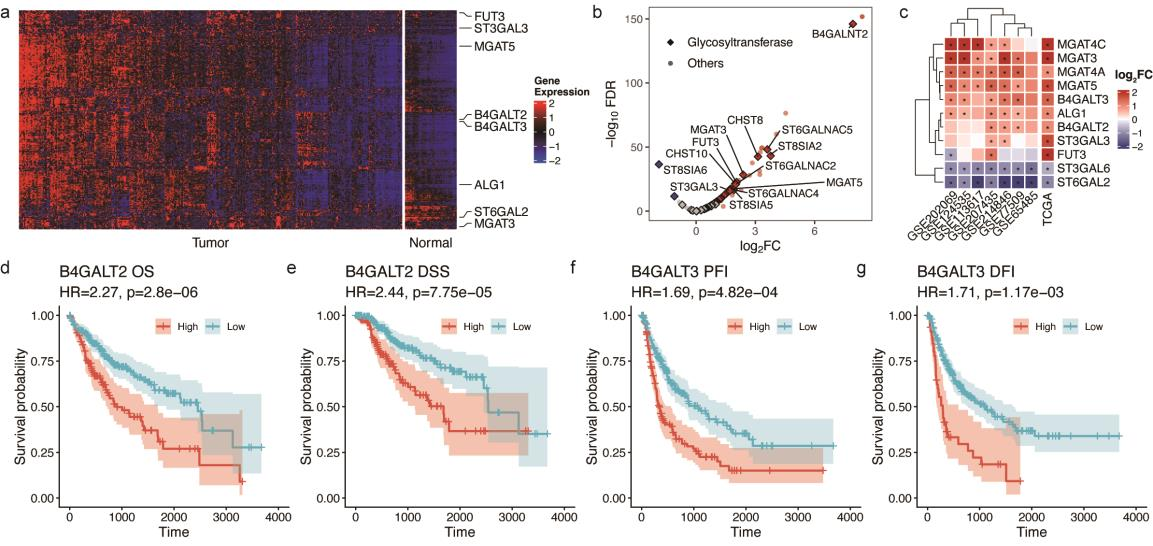
Fig. 6 TCGA与GEO数据集中的糖基化基因表达
06. 机器学习诊断模型的建立与验证
进一步,该研究选取了26种缺失比例低于1%的N-糖链用于训练基于机器学习的诊断模型。GZ -I队列被随机分为训练集(n=526)和内部验证集(n=218)。研究人员采用两个外部验证集(GZ -II队列n=186; XZ 队列n=144)评估模型的泛化能力(Fig.7a),开发了三种模型分别用于 HCC 与HC、 HCC 与 CHB、 HCC 与LC样本的分类。该方法支持预筛查策略,可为已存在慢性肝病的患者提供定制化 HCC 诊断(Fig.7b)。该研究采用最先进的AutoML技术,基于训练集上的交叉验证性能筛选出最优算法和超参数配置。所有三个模型在内部验证集和两个外部验证集(Fig.7c-e)中均展现出优异的分类性能。同时,研究人员还评估了模型4(PP4)在患者分层中的临床应用价值(Fig.7g–l)。这些结果表明,基于血清N-糖组的机器学习模型不仅优于甲胎蛋白(AFP)等传统生物标志物,还能通过稳健的分层分析和特征重要性分析,为肝病进展和癌症分期提供重要依据,为 HCC 精准诊断开辟了新途径。
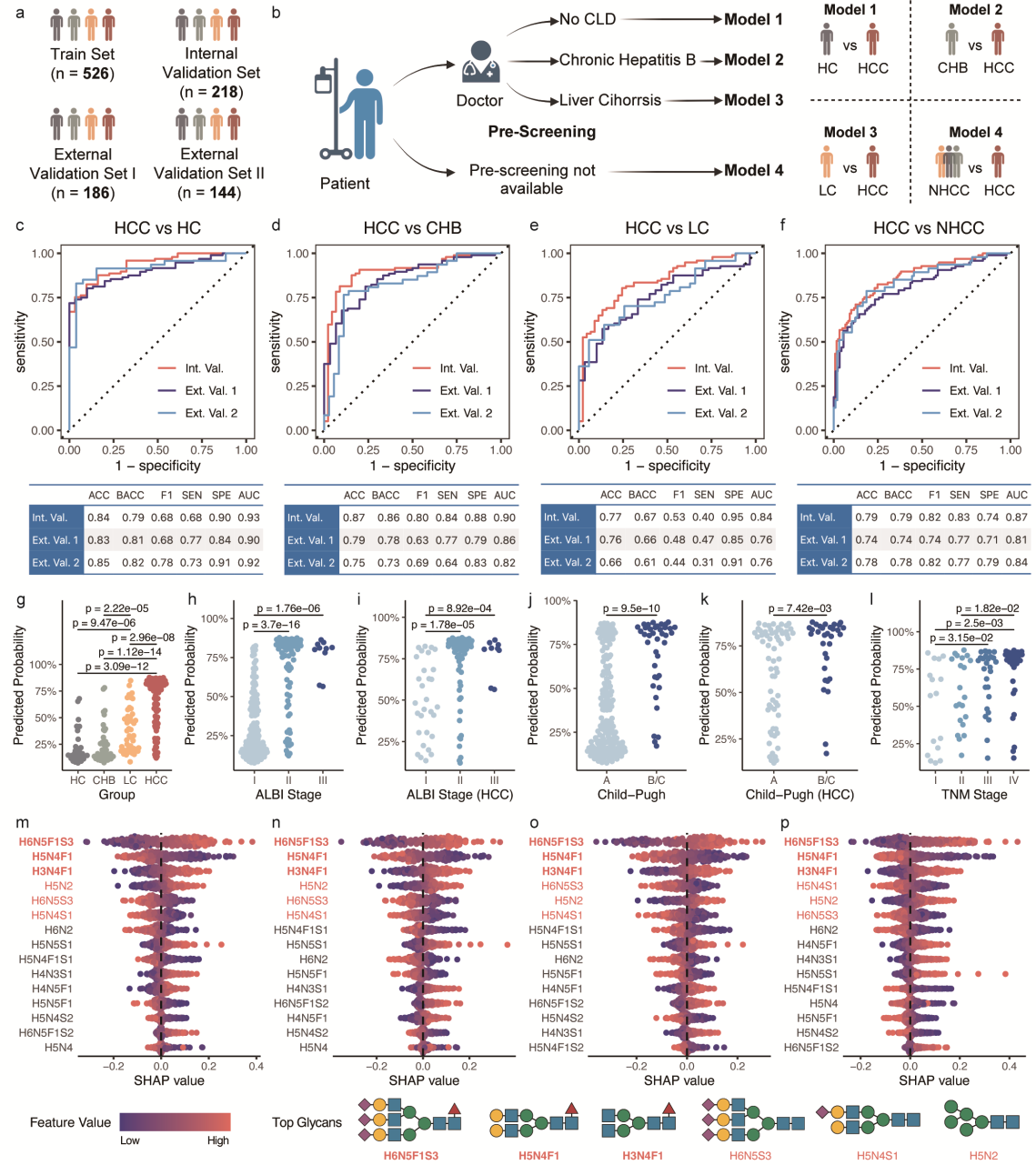
Fig. 7 机器学习诊断模型
总结与展望
本研究通过大规模多组学整合分析,系统刻画了HCC演进过程中糖基化的动态变化规律,并成功构建了高精度诊断工具,为肝细胞癌的早期发现、分子分型及发病机制研究建立了新的研究范式。血清N-糖组学有望成为肝病管理中继蛋白质标志物后的重要补充,拓展现有诊断体系。未来研究可结合单细胞测序等前沿技术,进一步深入解析肿瘤微环境的异质性特征,为精准医学提供更全面的分子图谱。
原文链接:https://www.nature.com/articles/s41467-026-68579-x
研究背景
肝细胞癌(HCC)是全球癌症相关死亡的主要原因之一,其早期诊断面临巨大挑战。目前临床常用的肿瘤标志物甲胎蛋白(AFP)灵敏度有限,难以满足早期筛查需求,因此迫切需要寻找高精度的非侵入性生物标志物。近年来研究发现蛋白质N-糖基化在肝脏疾病的发生发展过程中发挥关键调控作用,而血清N-糖基化谱的变化可能反映了肝脏的功能状态及恶性转化进程,为HCC的早期诊断提供了新的切入点。
2026年1月20日,复旦大学和广东省人民医院研究团队在Nature Communications上发表了题为 “Large-scale serum N-glycomics tracks N-glycosylation dynamics in hepatocellular carcinoma progression and enables early diagnosis” 的研究论文。本研究基于大队列样本系统解析了血清N-糖基化在HCC演进中的规律,既揭示了糖基化重编程的生物学机制,更开发出高精度诊断模型,为肝细胞癌的早期诊断和精准分型提供了新的解决方案。
文章标题
研究设计
队列样本:研究纳入1,074名中国受试者,覆盖健康对照(HC)、慢性乙型肝炎(CHB)、肝硬化(LC)和肝细胞癌(HCC)患者。
组学检测:高通量血清N-糖基化组学、位点特异性糖蛋白组学。
公共数据库资源:转录组学(TCGA/GEO数据分析)
Fig. 1 研究概述
研究结果
01. 血清N-糖基化与肝功能恶化显著相关
本研究通过探讨血清N-糖组学特征与肝功能检查以及肝功能评分系统白蛋白-胆红素(ALBI)分期和Child-Pugh分级之间的关联(Fig.2a)。发现N-糖组学特征与肝功能检查及肝功能评分系统均呈现显著相关性(Fig.2b)。其中,肝功能较差的患者表现为分支化、GlcNAc双切和岩藻糖基化增加,同时伴有半乳糖基化和唾液酸化减少(Fig.2c)。同时,不同疾病亚组水平上的相关性模式与整体水平保持一致,其中肝硬化(LC)和肝癌(HCC)队列显示出显著的一致性(Fig.2e-f)。这表明蛋白质N-糖链可有效反映肝功能恶化,可作为评估肝功能的可靠标志物。
Fig. 2 血清N-糖组学与肝功能的相关性研究
02. HCC特异性糖基化特征重塑
对比分析发现,在不同疾病组间,HCC 血清N-糖基化修饰水平改变最为显著(Fig.3c),其次是肝硬化(Fig.3b)。而慢性肝炎中几乎未观察到显著的N-糖基化修饰变化(Fig.3a)。在肝硬化中,下调的N-糖链主要为三触角和四触角结构,且多唾液酸化,缺乏岩藻糖基化(Fig.3b)。而岩藻糖基化、多唾液酸化的三触角和四触角糖链在HCC 中特异性上调(Fig.3c-d)。根据表达模式分析,48种显著失调的N-糖链被划分为五个糖链共表达模块(GCMs)(Fig.3e)。每个GCM均呈现独特的表达谱(Fig.3f)和结构特征富集(Fig.3g),且表达相似性较低(Fig.3h)。同时,在各类肝脏疾病中均观察到血清N-糖组的特征性结构改变(Fig.3i)。
Fig. 3 血清N-糖组与肝脏疾病的相关性
03. 基于N-糖基化谱的HCC分子分型
研究进一步通过血清N-糖组数据的无监督共识聚类分析,将HCC 样本划分成了三个独特亚型(Fig.4a)。各亚型均呈现独特的N-糖链特征谱(Fig.4b)。亚型1的特征表现为GCM3中含双切N-乙酰葡糖胺(GlcNAc)的小型未成熟糖链水平升高,而GCM2中大型多唾液酸化、无岩藻糖基化糖链水平降低(Fig.4c,Fig.3g)。亚型2则表现为GCM1中大分子多唾液酸化、岩藻糖基化糖链水平下降。亚型3表现出GCM1糖链增加,同时GCM5中高甘露糖、杂合或小复合糖链水平降低,其糖组学特征与亚型1部分互补。此外,各亚型与临床参数(如肝功能,疾病分期)显著相关:亚型1、3的肝功能差于亚型2,且亚型2多处于疾病早期阶段。
Fig. 4 基于N-糖基化谱的分子分型
04. 位点特异性糖基化分析
为进一步鉴定位点特异性糖基化,该研究采用DDA 精准模式对 GZ-I队列的一个子集(n=120,每组30例)进行正交N-糖蛋白质组学与蛋白质组学分析。共鉴定到 3,057 个糖肽、2,824 种位点特异性糖链、477 种糖链组成、276 个糖基化位点和 168 种糖蛋白。通过整合所有具有相同糖链组成的位点特异性糖链的定量数据,生成了伪糖组学谱。(Fig.5a)。这些伪糖组学谱与真实糖组学表现出高度一致性(平均Pearson相关系数r≈0.95),糖链显示出多样化的位点特异性贡献(Fig.5b-d)。而具有相似结构特征的糖链表现出相似的位点贡献(Fig.5d)。这些研究结果揭示了特异性位点对血清N-糖组中异质性的贡献,主要由一组高丰度糖蛋白驱动。
同时,研究人员选择那些在对应蛋白质丰度变化之外仍表现出显著改变的位点特异性糖链(SSGs)进行了差异分析(Fig.5e–g),并通过整合糖组学和糖蛋白组学数据,阐明了导致糖组改变的两种不同机制:糖基化主导机制和蛋白质主导机制。这为未来糖组学研究提供了重要启示:仅凭血清糖组数据可能不足以提供调控机制的深入见解。
Fig. 5 糖基化修饰的位点特异性分析
05. 糖基化相关酶的转录调控
蛋白质N-糖基化是一个高度调控的过程,由多种糖基转移酶、糖苷酶及其他调控因子的有序作用所控制。为探究这些酶及调控因子的改变是否参与驱动 HCC 中观察到的N-糖基化变化,该研究分析了 TCGA - LIHC 数据集中的基因表达数据。在肝肿瘤组织中观察到糖基因的全局上调(Fig.6a)。差异表达分析(DEA)显示118个糖基因表达上调,仅有两个糖基因表达下调(Fig.6b),表明肿瘤细胞中N-糖基化整体增强。值得注意的是,催化N-糖链生物合成初始步骤、组装脂质连接寡糖前体、寡糖基转移酶复合体基因显著上调,表明 HCC 细胞不仅增强了初始糖基化生物合成,还提升了转移步骤效率,从而强化了N-糖基化整体格局。糖基因表达模式同时在7个GEO数据集中得到了验证(Fig.6c),表明在不同人群中存在高度保守的疾病相关糖基化失调。
最后,通过生存分析筛选具有预后价值的糖基因,半乳糖基转移酶成为关键预后指标:B4GALT2与总生存期显著相关(Fig.6d-e),而B4GALT3则与疾病进展密切相关(Fig.6f-g)。这些发现表明糖基化修饰可能在调控疾病进展和预后中发挥重要作用,为未来治疗干预提供了潜在靶点。
Fig. 6 TCGA与GEO数据集中的糖基化基因表达
06. 机器学习诊断模型的建立与验证
进一步,该研究选取了26种缺失比例低于1%的N-糖链用于训练基于机器学习的诊断模型。GZ -I队列被随机分为训练集(n=526)和内部验证集(n=218)。研究人员采用两个外部验证集(GZ -II队列n=186; XZ 队列n=144)评估模型的泛化能力(Fig.7a),开发了三种模型分别用于 HCC 与HC、 HCC 与 CHB、 HCC 与LC样本的分类。该方法支持预筛查策略,可为已存在慢性肝病的患者提供定制化 HCC 诊断(Fig.7b)。该研究采用最先进的AutoML技术,基于训练集上的交叉验证性能筛选出最优算法和超参数配置。所有三个模型在内部验证集和两个外部验证集(Fig.7c-e)中均展现出优异的分类性能。同时,研究人员还评估了模型4(PP4)在患者分层中的临床应用价值(Fig.7g–l)。这些结果表明,基于血清N-糖组的机器学习模型不仅优于甲胎蛋白(AFP)等传统生物标志物,还能通过稳健的分层分析和特征重要性分析,为肝病进展和癌症分期提供重要依据,为 HCC 精准诊断开辟了新途径。
Fig. 7 机器学习诊断模型
总结与展望
本研究通过大规模多组学整合分析,系统刻画了HCC演进过程中糖基化的动态变化规律,并成功构建了高精度诊断工具,为肝细胞癌的早期发现、分子分型及发病机制研究建立了新的研究范式。血清N-糖组学有望成为肝病管理中继蛋白质标志物后的重要补充,拓展现有诊断体系。未来研究可结合单细胞测序等前沿技术,进一步深入解析肿瘤微环境的异质性特征,为精准医学提供更全面的分子图谱。
原文链接:https://www.nature.com/articles/s41467-026-68579-x


