







西湖欧米于2024年1月30日举办的 “解码队列研究:揭秘临床血液大队列蛋白质组研究思路” 线上直播,邀请了中国医学科学院血液病医院王洪研究员、西湖大学蛋白质组大数据实验室博士生蔡雪、西湖欧米技术高级科学家张程分别做了精彩分享,直播期间也得到了观众们的热烈关注。
让我们一起来看看直播的精彩回放吧!
(直播精彩视频片段见西湖欧米公众号)
中国医学科学院血液病医院王洪研究员:
Blood ecosystem approach to dissect systemic diseases
讲座概要:针对健康对照及不同时期新冠患者,提取多种血液样本类型(外周血单核细胞、血浆、血小板)进行多组学(单细胞转录组学,bulk蛋白组学、代谢组学)联合分析,研究新冠患者血液生态系统多组学特征表达谱并用随机森林模型预测新冠复阳概率。
精彩瞬间
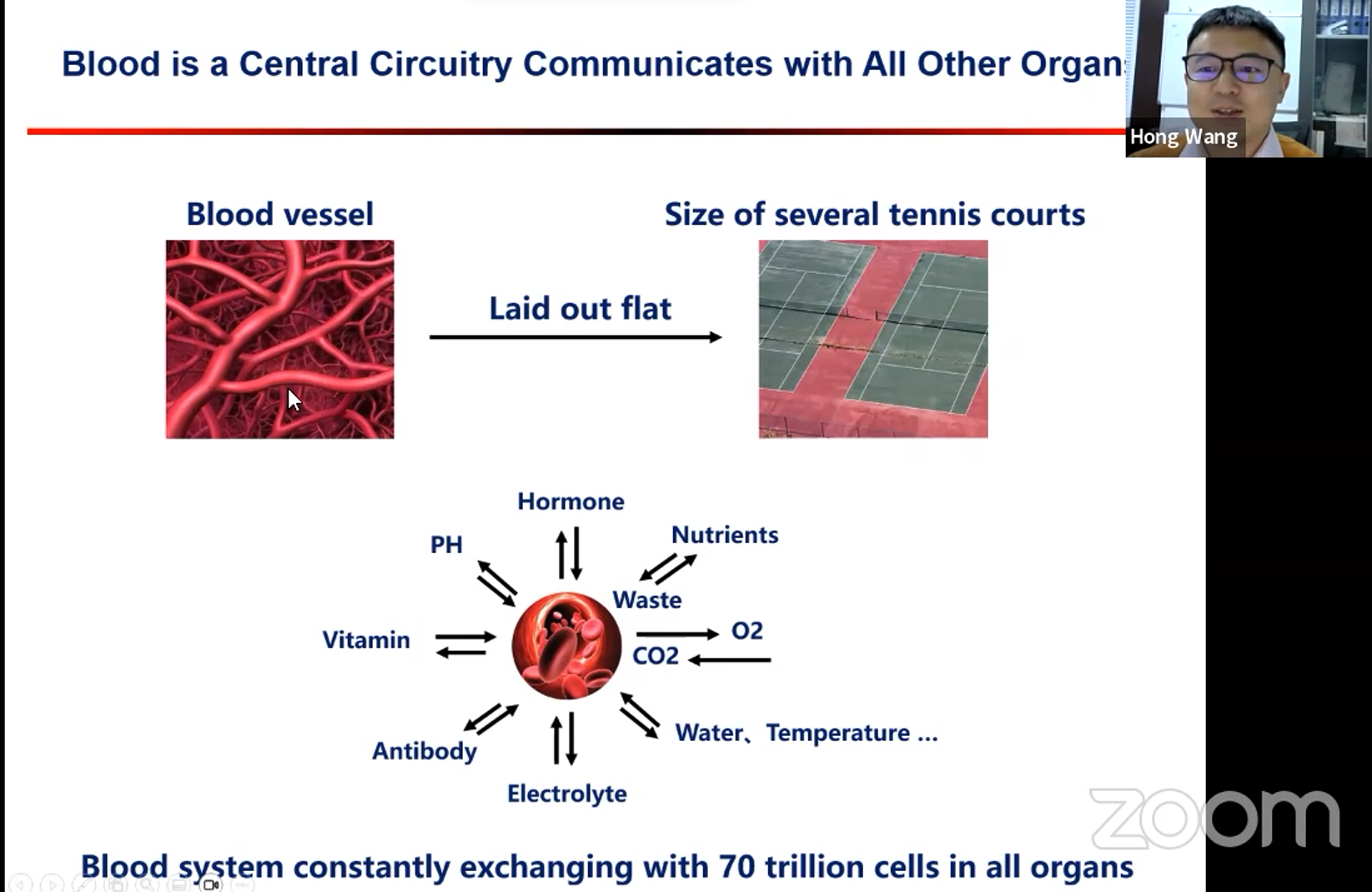
1. 血液生态系统的重要作用:血液不断与机体内70万亿细胞进行物质交换,运输氧气、二氧化碳、营养物质等,在机体生理病理中发挥着重要作用。
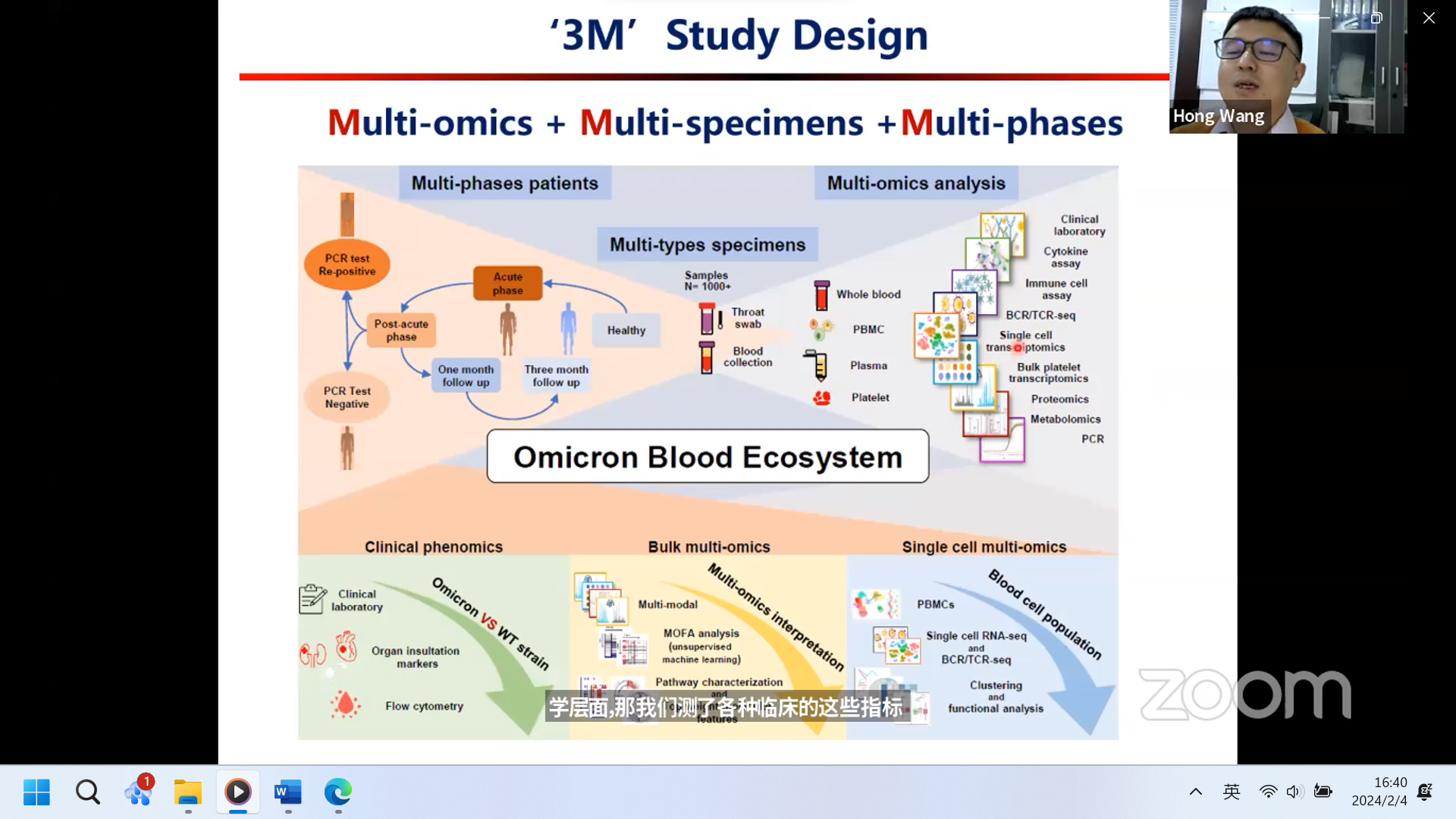
2. 文章特色:对多样本类型、多疾病阶段进行多组学检测。
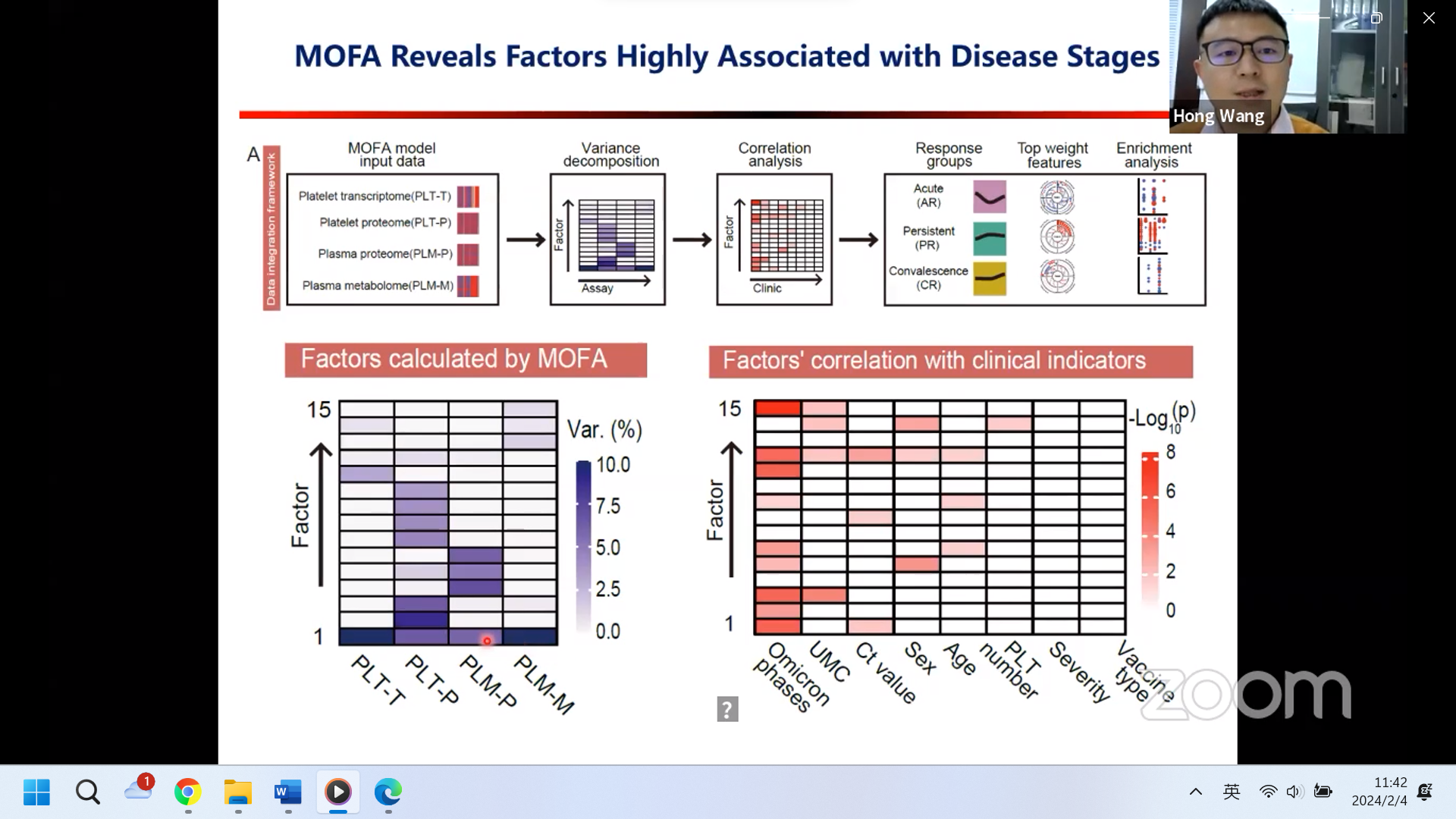
3. Multi-Omics Factor Analysis(MOFA)是一种多组学数据集集成和分析的方法,旨在揭示多个组学层面之间的共变关系和潜在因素,适用于多组学数据整合分析。
西湖大学蛋白质组大数据实验室博士生蔡雪:
万例人群血清蛋白质组学前瞻性预测代谢综合征风险
讲座概要:本研究收集万例血清样本进行蛋白组学研究,将队列随机分为发现集、验证集,研究蛋白组学对代谢综合征的诊断效能。
精彩瞬间
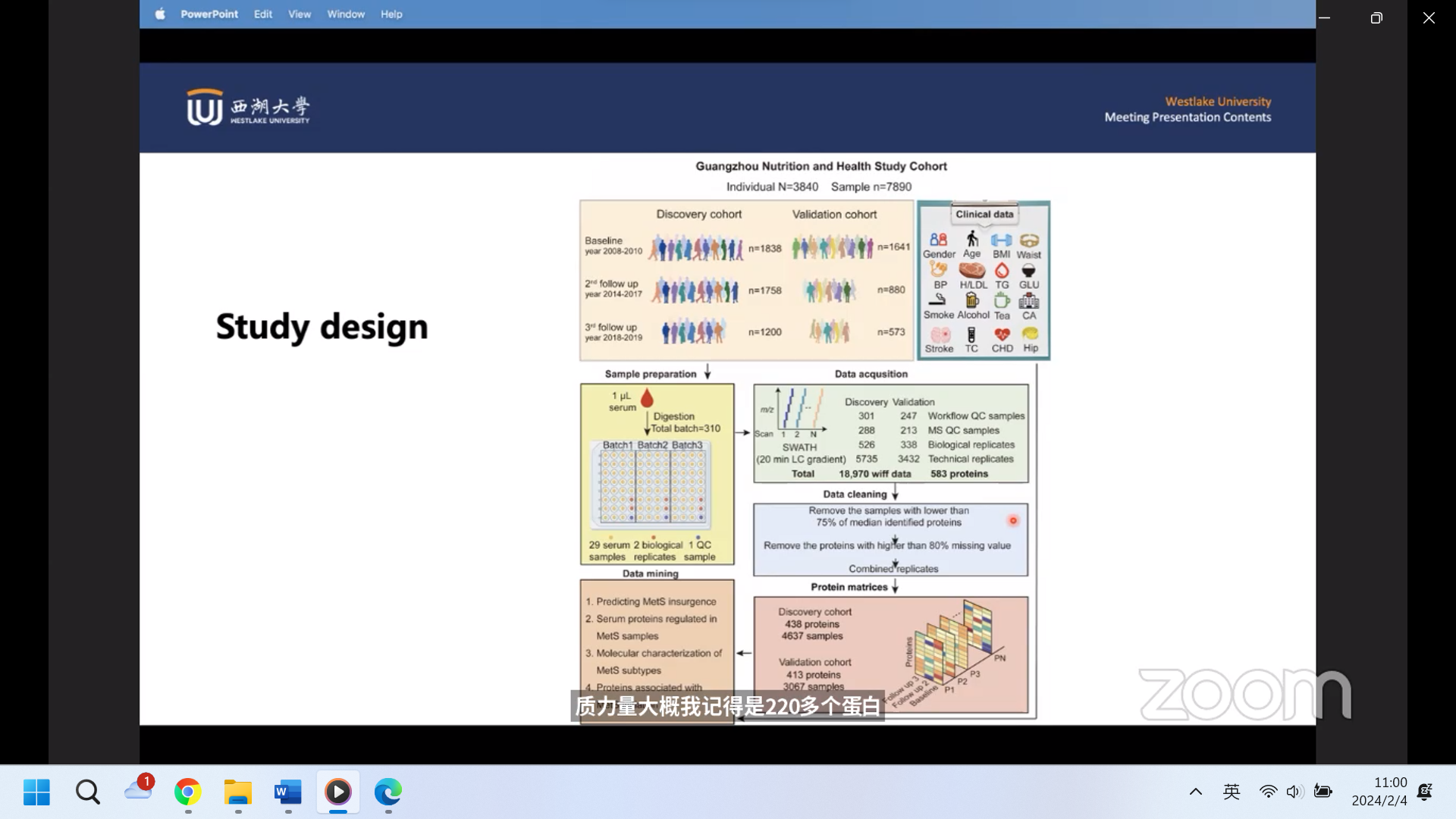
该研究设计严谨,对三千多人的大队列进行两次随访,收集万例血清样本进行蛋白组学研究,并对数据进行严格的质控。将大队列随机分为发现集、验证集,研究蛋白组学对代谢综合征的诊断效能。
西湖欧米技术高级科学家张程:
西湖欧米血液大队列蛋白质组解决方案
讲座概要:西湖欧米血液大队列蛋白质组学解决方案,及OmniProt去除高丰度血液蛋白等西湖欧米特色产品服务介绍。
精彩瞬间
1. 西湖欧米以蛋白质组学为核心,联合其他组学为大家提供多组学一站式服务。针对客户的个性化需求,我们会进行文献调研、实验生信等流程开发,助力老师血液大队列相关研究。
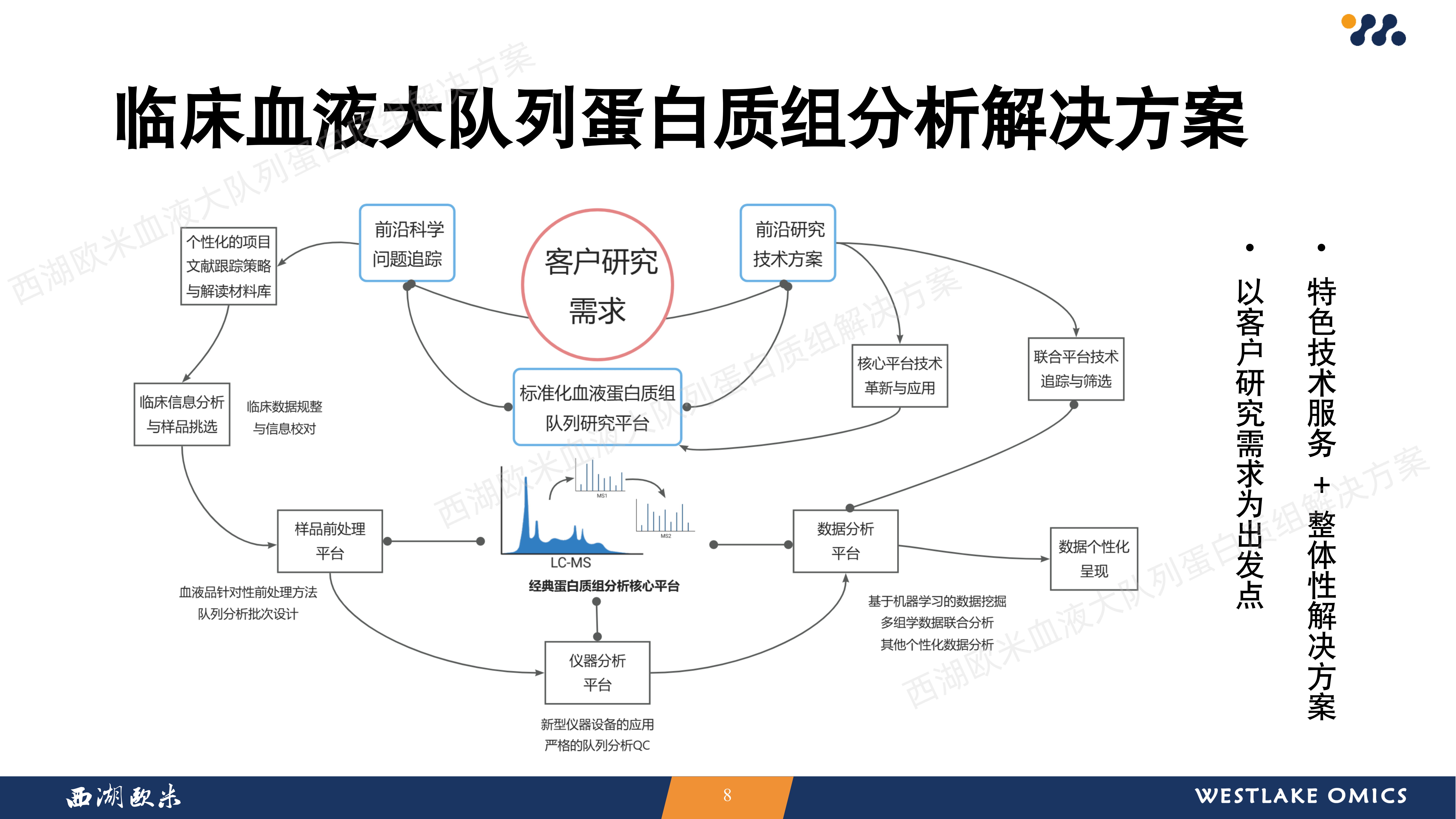
2. 用OmniProt技术去除血液高丰度蛋白,显著增加了血液蛋白鉴定量。
3. 稳健的QC方案有助于提高重现性,提升定量准确性。
直播期间,观众朋友们在线提出了很多关于大队列的问题。我们收录了嘉宾们的一些回复,在此分享给大家:
Q1 血细胞、血浆、血小板、PBMC分别适合研究什么?
A1 血液成分非常复杂。血细胞有各种类型,适合从单细胞层面进行研究,技术上比较适合单细胞测序,而单细胞蛋白组还需要技术的突破。血小板是无核细胞,基因组很少,不太适合测序,更适合蛋白、代谢的相关探索。血浆中含有丰富的蛋白质,可进行蛋白质组学研究,用于研究生物标志物、疾病诊断等。PBMC为血液中的白细胞,包括淋巴细胞、单核细胞等,适用于基因表达、蛋白质表达等研究。
Q2 如何降低批次效应?
A2 首先在样本制备、人为采集阶段,针对不同年龄、性别等,我们采用随机抽样的方法,使其均匀分散在不同组。质谱上机时,每个batch都有生物学重复、技术重复。多台仪器同时采集,用算法降低批次效应的影响。整个数据集没有明显的batch,再进行后续分析。
Q3 (在做万例血清蛋白组学研究时)请问您选用的特征筛选方法是什么,为什么在众多方法中使用这一种?
A3 建模是用训练集,用了很多种机器学习、特征筛选的方法进行尝试,选择最佳模型,后续在测试集中进行验证。
Q4 做MOFA分析的适用条件是什么?多组学数据是否都适用?最少是几个组学?
A4 Multi-Omics Factor Analysis(MOFA)是一种多组学数据集集成和分析的方法,适合多模态,使用时应考虑以下几个方面:1)数据类型:MOFA可以处理多种类型的组学数据,包括但不限于基因表达、蛋白质表达、代谢物浓度、表观遗传学等;2)样本量:MOFA在处理多组学数据时对较大的样本量可能更有优势。通常情况下,至少需要几十个样本,以获得稳健和有意义的结果。较小的样本量可能会限制模型的可靠性。最少是两个组学,便可进行MOFA分析。
Q5 血小板提取应该注意什么?
A5 血小板提取主要基于离心,很容易在提取时激活,离心速度不稳定时,血小板在血细胞和血浆中的成分就会改变,所以一定要注意离心速度和时间。
Q6 AI生信分析、数据挖掘在临床血液大队列中的应用?
A6 AI是个广泛的概念,目前我们队列研究中常用到的是机器学习。在生物医药的应用主要应用于分类和诊断。比如,如何区分两种疾病,疾病对药物的敏感性,疾病的转归等。我们可以做蛋白质组学或其他组学,从多个fearure中进行筛选,降维,用机器学习建模,判断生物标志物的诊断效能。
Q7 在博士期间做万例的大队列很难得,可以分享下经验吗?
A7 首先在样本收集阶段,记录好各种样本信息(包括临床信息、收集时间、可能的异常等),质谱上机时,设计好QC样本,包括pool样以及技术重复。质谱采集时,也要时常观察仪器情况,若有异常,及时和前面的记录核对,找出原因,及时解决。数据分析时,观察是否有批次效应,若有,用算法降低。
针对队列研究,西湖欧米在前处理质控设计、质谱上机处理、数据分析处理方面均有丰富经验。
各位老师若有兴趣,欢迎垂询。



