







2023年8月30日,西湖大学郭天南、郑钜圣及中山大学陈裕明教授,共同通讯在 Cell Reports Medicine 在线发表了题为 “Population serum proteomics uncovers a prognostic protein classifier for metabolic syndrome” 的研究论文。该研究基于一个随访10年以上的社区队列人群建立了近2万例血清蛋白质组学数据库,并构建了机器学习模型前瞻性预测代谢综合征在10年内的患病风险(图1)。西湖欧米负责该研究的数据分析工作。
代谢综合征(MetS)是一种复杂的代谢紊乱,其特点为腹部肥胖、动脉粥样硬化性血脂异常、高血压、胰岛素抵抗、中心性肥胖、促凝血和促炎症状态。全球成年人中约有20-25%患有MetS。中国成年人中,2018年MetS的患病率达到24.2%(男性24.6%,女性23.8%)。
MetS可导致几种严重疾病,包括糖尿病、心血管疾病、冠心病和一些常见癌症。早期预测和诊断MetS将有助于更快地进行干预,减轻医疗系统的负担。因此,纵向的大型队列人群研究是必要的,可以有效预测MetS的发展并探索其发病机制。
基于质谱(MS)的蛋白质组学的快速发展为大规模队列蛋白质组学研究提供了坚实的技术支持。该项技术能够以极小的样品量(微升级)进行高通量、可重复的分析。数据非依赖性采集(DIA)质谱可以测量所有离子化的多肽母离子,适合于在大规模人群中无偏倚地发现新的生物标志物。
在这项研究中,我们收集了来自3840名参与者,十年两次随访的7890个样本。我们使用DIA-MS方法检测了约20,000个蛋白质数据中的400多个蛋白质。
基于这个血清蛋白质组学库,我们建立了一个机器学习模型用于预测在十年内发展为代谢综合征的风险。此外我们还探索了与代谢综合征相关的新潜在生物标志物和通路,为代谢综合征的发病机制和靶向治疗提供了参考。
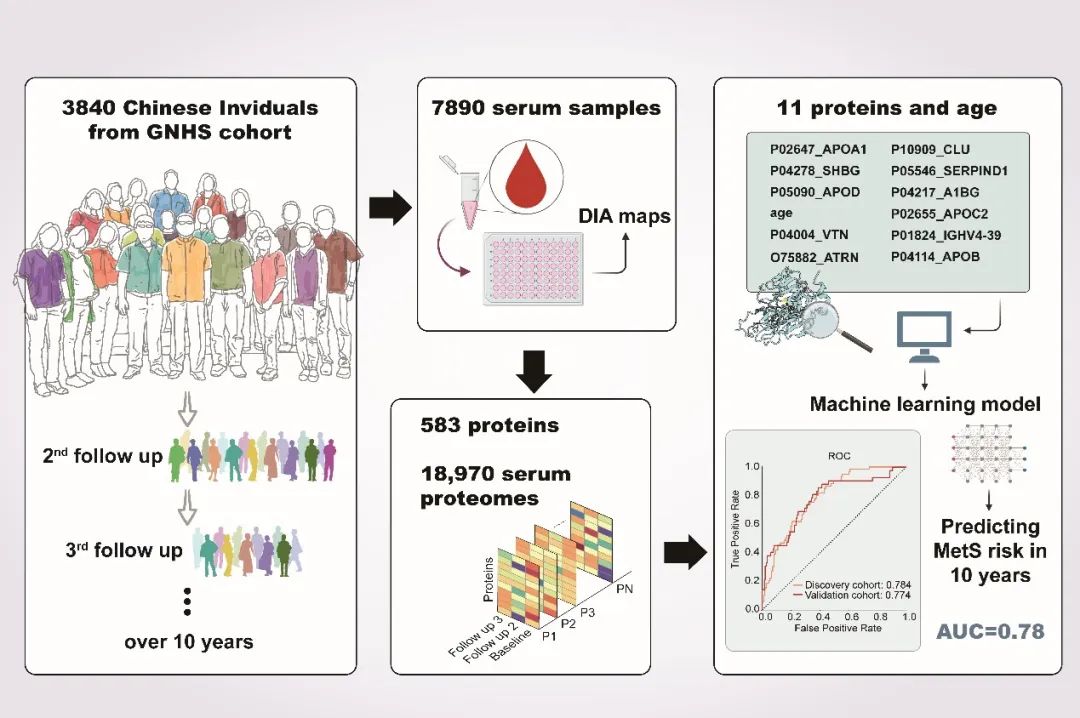
图1 研究内容概览
纵向人群队列的血清蛋白质组学分析
我们纳入了3840名来自广州营养与健康研究队列(GNHS,ClinicalTrials.gov标识符:NCT03179657)的参与者。血清样本在三个时间点进行采集:3479份样本在基线(2008年至2010年)采集,2638份样本在第二次随访(2014年至2017年)采集,1773份样本在第三次随访(2018年至2019年)采集。
基线、第二次随访和第三次随访组的中位年龄分别为57.4岁(38.2-80.4岁)、63岁(44.3-83.3岁)和66.1岁(46.8-86.2岁),其中女性参与者占比分别为69%、68%和69%。随后,我们将血清样本随机分为发现队列(n=4794)和验证队列(n=3094)(图2),然后进行独立的样本制备、质谱数据采集和数据分析。
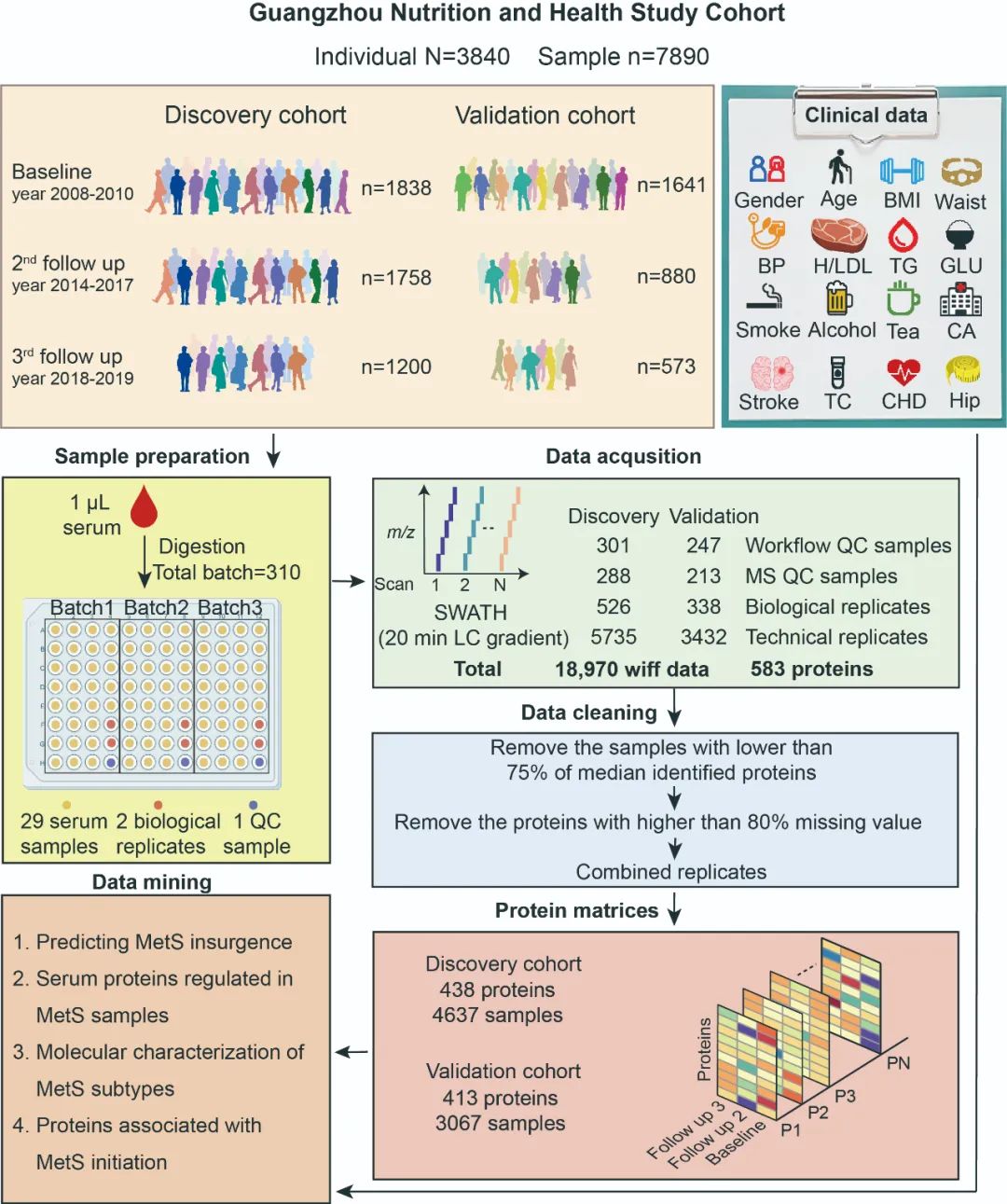
图2 人群队列的血清蛋白质组学数据采集流程
根据年龄和性别,我们随机将4796份发现队列血清样本分成178个批次样本,每批包含29份血清样本、两份生物学重复样本(血清样本重复处理两次)和一份质控(QC)样本(混合血清样本),此外我们还纳入了质谱质控样本(混合多肽样本,MS-QC)和技术重复样本(多肽样本重复进样两次)以确保整个工作流程的稳定性(图2)。
使用DIANN软件,我们得到了一个包含583个蛋白质和11,646个质谱数据的蛋白矩阵。接着我们排除了低鉴定量(低于中位数蛋白鉴定结果的75%(<245))的样本和高缺失率(超过80%)的蛋白质,并使用ProteomeExpert 对批次效应进行了校正(图3B)。
我们同样评估了质谱质控样本,生物重复,技术重复的中位数皮尔逊相关系数(r),结果显示了整个工作流程中质谱仪的高稳定性,数据的高一致性和可重复性(图3A, C)。我们将r > 0.8的重复数据的定量结果进行了填充与合并,用于后续的数据分析。同样的数据处理方法也应用于验证队列的数据处理中。
最后,在发现队列中,我们获得了一个包含4637个样本和438个蛋白质,缺失值为19.0%的蛋白质矩阵(图2);在验证队列中,我们获得了一个包含3067个样本和413个蛋白质,缺失值为18.4%蛋白质矩阵(图2)。
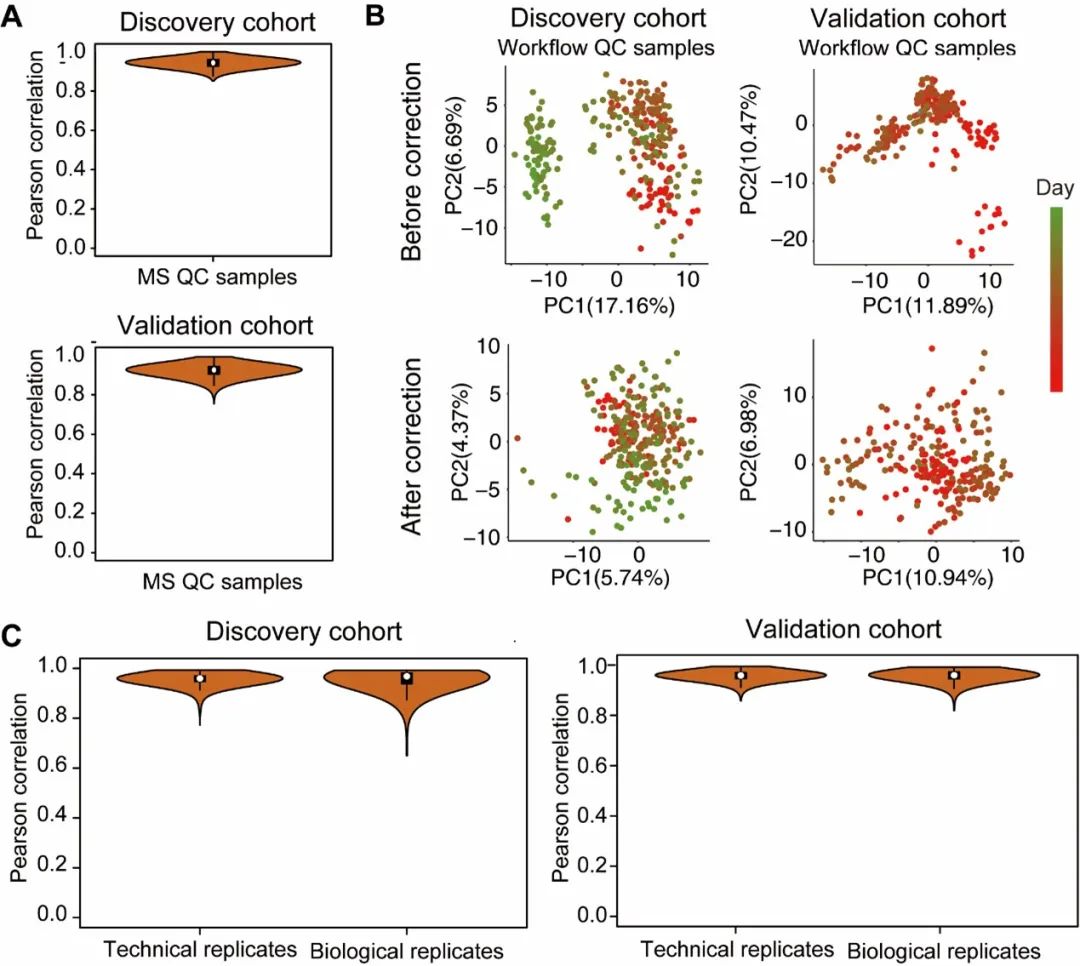
图3 质控数据结果
基于蛋白质,用于预测代谢综合征发生的分类器
对于发现队列,我们在基线时间点收集了一组样本(图4A),包括第二或第三次随访时被诊断为代谢综合征的267个非代谢综合征样本(实验组)和任何时间点都未被诊断出代谢综合征的588个非代谢综合征样本(对照组)。
利用这些数据,我们构建了一个机器学习模型来评估血清蛋白质预测在十年内发生代谢综合征的风险的能力(图4B)。最终模型的特征包括载脂蛋白A-I(APOA1)、性激素结合球蛋白(SHBG)、载脂蛋白D(APOD)、年龄、玻连蛋白(VTN)、吸引素(ATRN)、簇因子(CLU)、肝素辅因子2(SERPIND1,HCII)、α-1B-糖蛋白(A1BG)、载脂蛋白C-II(APOC2)、免疫球蛋白重链变量区域4-39(IGHV4-39)和载脂蛋白B-100(APOB)(图4C)。
我们使用随机选择的内部验证数据集对模型进行测试,得到AUC为0.784,表明我们的模型可以有效预测在十年内发生代谢综合征的风险(图4D)。最后,我们使用来自独立验证队列的242个样本进行模型测试,得到AUC为0.774(图4D)。
由于验证队列的样本数量相对较小,与发现队列相比,所选特征在模型应用于验证队列时的显著性排名可能会波动。然而,主要特征,如APOA1、年龄、APOD和VTN仍然相对稳定(图4C)。这些结果表明所选特征是稳定的,可以很好地推广到独立采集的样本,并且在模型中使用的蛋白质可能作为有前景的生物标志物候选者。
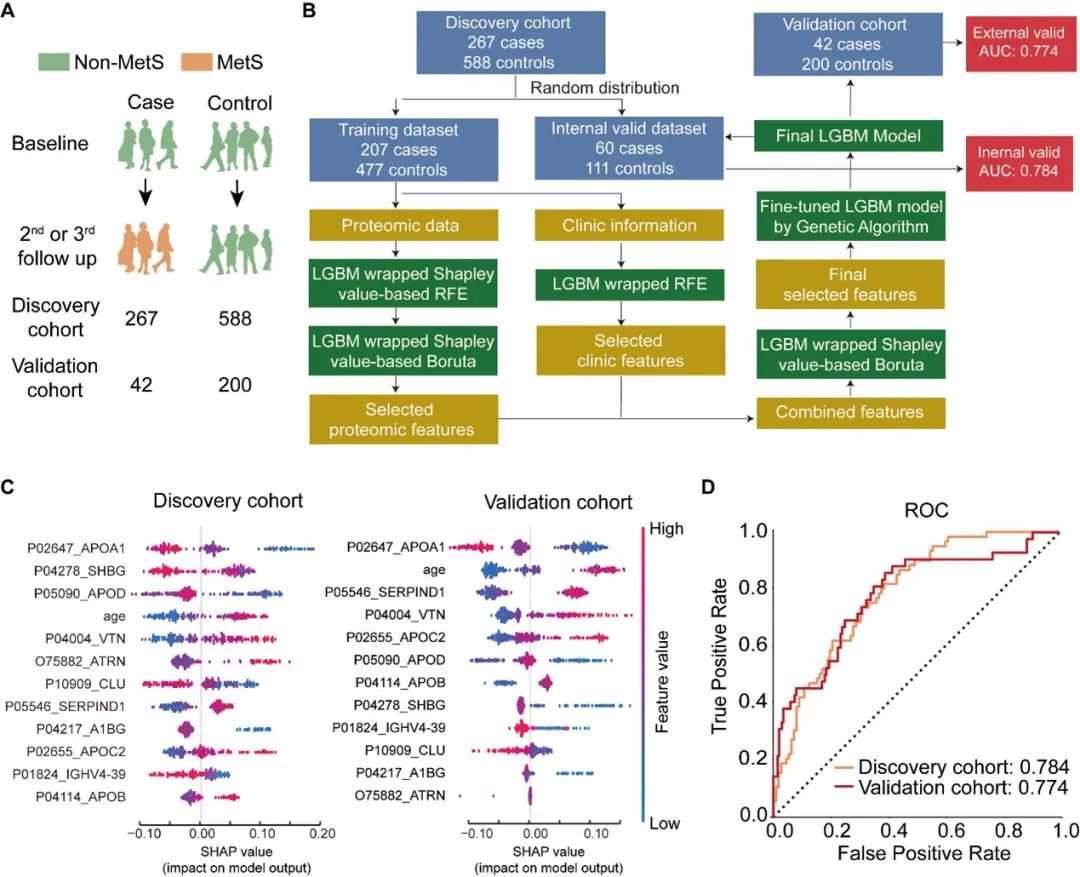
图4 机器学习模型构建流程和结果
该研究也存在一定的局限性。首先,我们使用了一个短梯度、高通量蛋白质组学工作流程,这更适合于分析人群队列样本,相对的,我们鉴定到的血清蛋白的深度有限。其次,我们的发现和验证队列来自同一个城市。因此,我们的结果需要应用于来自不同地区的独立人群进行后续研究。
西湖实验室的西湖智能蛋白质组中心(www.prottalks.com),聚焦人工智能赋能的蛋白质组研究,致力于蛋白质组大模型的建设和转化。
西湖实验室郭天南团队蔡雪、薛张芝,岳靓,暨南大学曾芳芳,西湖实验室郑钜圣团队唐俊,西湖欧米(杭州)的王博为共同第一作者;西湖实验室郭天南、郑钜圣研究员、朱怡副研究员,中山大学陈裕明教授为共同通讯作者。本项研究得到了西湖实验室、西湖大学高性能计算中心、西湖教育基金会以及国家自然科学基金、浙江省自然科学基金等基金项目的资助。
论文链接:
https://www.cell.com/cell-reports-medicine/fulltext/S2666-3791(23)00325-7


