蛋白质宇宙,图源自mkai.org
心理学上有一个著名的 “街灯效应(streetlight effect)”:在路灯下找寻已知或拥有的事物,而真正所需的未知事物则在 “未充分研究” 的黑暗之处。
在科学上,蛋白质的研究现状正如 “街灯效应”:迄今为止,大多数蛋白质研究都集中在部分熟知的蛋白质上,而我们对其他成千上万蛋白质的生物学功能仍然知之甚少。
为了更好地了解哪些人类蛋白质仍然缺乏及其原因,去年5月,六国科学家联合发起了一项名为 “未充分研究的蛋白质计划(Understudied Proteins Initiative)” 的调查,发起者中有Juri Rappsilber教授、西湖大学郭天南教授等。
未充分研究的蛋白质如果能与人工智能系统结合,势必让我们一窥蛋白质世界更为精彩的奥秘。
徐诗露 | 撰文 李晓韦、叶水送 | 责编
蛋白质是细胞的重要成分。它的存在赋予了生命体多种多样的功能,如肌肉组织结构纤维的形成、食物的酶消化或遗传信息的传达等。还有一些蛋白质,比如抗体,能保护生物体免受感染;又或是激素,能在生物体中传递重要的信号等。
可以说,蛋白质是从病毒到人类绝大多数生物的物质基础,是生命活动的主要承担者。毫不夸张地说,没有蛋白质就没有生命。
♦ 对蛋白质世界的探索,从未停止
多年来,国内外的科学家一直在进行蛋白质的研究。从20世纪30年代发明的透射电子显微镜,到近10年出现的冷冻电镜,再到如今可预测蛋白质结构的人工智能系统AlphaFold2…… 随着技术进步和学科融合,研究蛋白质的方法也在不断更新和进步。
2003年,历时13年的 “国际人类基因组计划(HGP)” 正式完成。但仅仅测绘出人类基因组序列,并非这一计划的最终目的,必须对作为其编码产物的蛋白质组进行系统深入的研究,才能真正实现基因诊断和基因治疗。
因此,在HGP完成之际,国际人类蛋白质组计划(HPP)随之启动,首批行动分 “人类肝脏蛋白组计划” 和 “人类血浆蛋白质组计划” 两部分同步进行。
2010年,人类蛋白质组组织(HUPO)再次正式启动HPP,旨在为全球合作、数据共享、质量保证和增强基因组编码蛋白质组的准确注释创建一个框架。正式启动后的这10余年里,该计划取得了诸多成就。
2014年,研究人员使用高分辨率傅里叶变换质谱法提出了人类蛋白质组的绘制图,对30个组织学正常的人类样本进行了深入的蛋白质组学分析,鉴定出由17000多个基因编码的蛋白质,约占人类注释蛋白质编码基因总数的84%。这是人类蛋白质组的第一张草图。

2014发表在Nature上的文章A draft map of the human proteome(人类蛋白质组草图),研究者绘制了人类蛋白质组的大部分图谱 图源:nature.com
随后,2020年(即HPP正式启动后十周年之际),这项计划取得了里程碑式的进展:精确地覆盖了90.4%的人类蛋白质,这一成果为疾病预防和个体化医学提供了重要思路。

2020年发表在 Nature communications 上的文章,研究者绘制出了人类蛋白质组学的第一个序列草图 图源:nature.com
此后,HPP继续致力于鉴定剩下10%的人类蛋白质。但是后续的研究或许会更加困难和缓慢,因为许多特殊蛋白质要么只在特定和难以获得的组织类型中表达,要么很难使用传统的蛋白质组学技术对其进行分离和分析。
即便已经有90%的蛋白质被鉴定出来,也并非所有蛋白质都得到了充分的研究。HPP主席、系统生物学研究所蛋白质组学中心主任罗伯特·莫里茨(Robert Moritz)指出,“绝大多数研究都是针对少数种类的蛋白质开展的,因为它们很容易被检测到,而且试剂是现成的。”
因此,即便HPP已经颇有成就,但依然有无数的蛋白质笼罩在迷雾之中,甚至有很大一部分蛋白质的研究依然坐在冷板凳上,无人问津。这也是为什么我们需要一个新的计划,来研究这些鲜有人涉及的未充分研究的蛋白质——这就是上面提及的Rappsilber、郭天南等六国学者发起的新计划:“未充分研究的蛋白质” 计划(Understudied Proteins Initiative)。
♦ “未充分研究的蛋白质”计划:让冷门蛋白质不再冷门
在蛋白质方面的专家看来,我们对人类蛋白质组的研究,95%的发表作品都在关注5000种已得到充分研究的人类蛋白质,许多与疾病相关的未表征的蛋白质,并没有得到很好的研究。
据美国食品与药品监督管理局(FDA)批准药物的作用靶点的分析,“目前只有5-10%的潜在靶标蛋白质被加以开发”。
为了解决这些重要蛋白质的相关研究 “坐冷板凳” 的问题,“未充分研究的蛋白质” 计划应运而生。Nature Methods 和 Nature Biotechnology 上同时发表了两篇重要文章,呼吁学界通过系统地关联未表征的蛋白质和已知功能的蛋白质,缩小两者之间的注释差距,从而为详细的机制研究奠定基础。


未被充分研究的蛋白质到底有多重要?这项计划的发起者认为,对它们进行研究,一方面有助于我们对基本的生命规律理解;另一方面,从药物发现的角度来看,能提高我们对蛋白质与小分子以及蛋白与蛋白间相互作用的理解,从而更好地指导药物开发工作。
根据项目发起者在 Nature Methods 中介绍,研究者计划分三步走,具体如下:
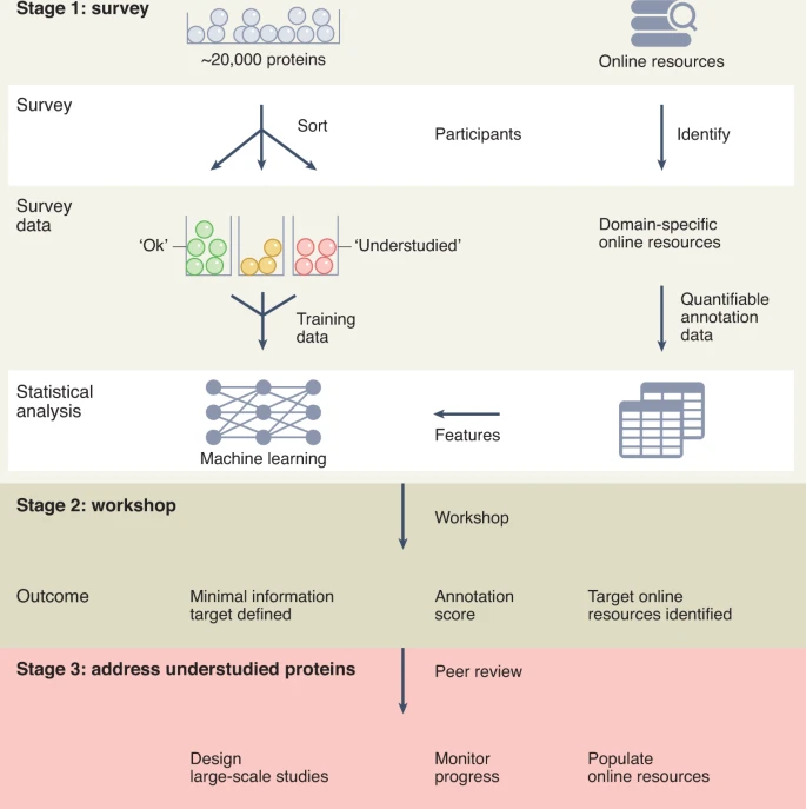
未充分研究蛋白计划路线图 图源:nature.com
第一步,明确定义目标。如果功能蛋白质组学的作用是推动对未充分表征蛋白质的机制研究,那么科学家们开始此类工作所需的最基本信息是什么?这个问题只能由在分子和机制方面详细阐明单个蛋白质在细胞中的功能的科学家才能回答。最终,实验室科学家和审核者的主观判断,决定了哪些蛋白质应该被详细研究。
第二步,建立一个由有志于该领域的科学家组成的团队。该计划由惠康信托基金(Wellcome Trust)支持,并计划举行会议,启动这一项目。会议将讨论上述调查的结果,对 “未充分研究蛋白质” 计划目标的影响,以及如何监测这些目标的进展。这将助力开放式讨论,哪些技术或发展能够系统地释放目前生物医学研究中未表征的蛋白质的潜力?从而促进领域内更多发展。
第三步,确定未充分研究的蛋白,设立研究计划以及监督工作进展等。
毫无疑问,对未充分研究的蛋白的探索意义重大,或许能给生物学研究以及药物开发带来前所未有的局面。但做好这个项目也并非易事,它也是科学界的一大难题。
♦ 人工智能和蛋白质研究的 “双向奔赴”
虽然研究者面临诸多挑战,但现在他们握在手里的工具越来越丰富、越来越先进了。2020年底,在国际象棋和围棋领域崭露头角后的人工智能(AI),再次在科学领域大出风头:DeepMind开发的人工智能系统AlphaFold2在国际蛋白质结构预测赛中摘得桂冠,并破解了一个困扰人类50年的难题:预测蛋白质的整体结构。
中国科学院院士、西湖大学校长施一公对此表示:“这是人工智能对科学领域最大的一次贡献,也是人类在21世纪取得的最重要的科学突破之一。”
可以说,这一成果引起了生命科学界的强烈反响。与此同时,人工智能也承载了更为重大的期许:AlphaFold2能否在蛋白质研究领域大放异彩,帮助科学家加速 “未充分研究蛋白质” 计划的进展?
AlphaFold2给蛋白质领域带来令人耳目一新的变化,要从2021年7月算起。当时,英国DeepMind公司宣布,AlphaFold2成功预测出98.5%的人类蛋白质结构。AlphaFold2运用了机器学习算法,配置了深度学习神经网络,并且接受了蛋白质数据库(PDB)和其他数据库中数十万个实验确定的蛋白质结构和序列的训练,因此它可以通过已知的基因序列预测出蛋白质的结构。
值得一提的是,他们将这些结构放入公开的数据库,并发布了AlphaFold2的开源代码,免费供全球科研人员使用。
短短一年后的2022年7月28日,DeepMind公司又宣布,AlphaFold2已经预测了超过2亿个蛋白质结构。这次的扩展不再仅仅着眼于人类蛋白质,而是包括植物、细菌、动物和其他生物体在内的各种物种的蛋白质结构。
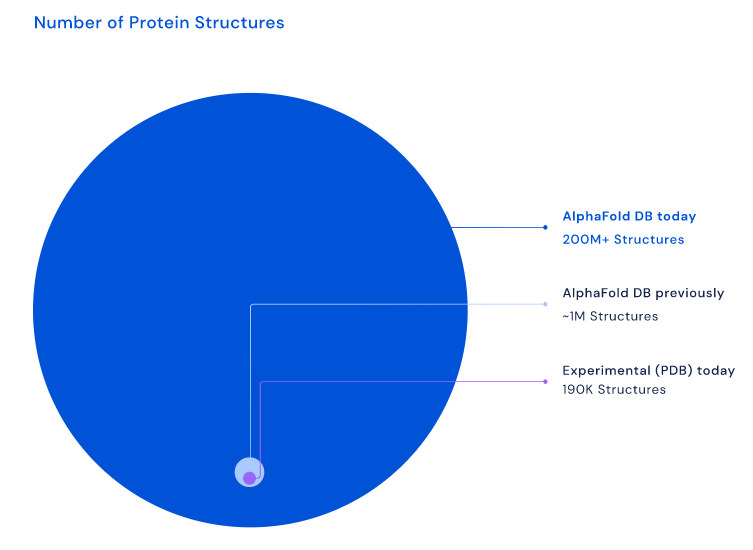
蛋白质结构的数量,AlphaFold2大大扩充了我们对蛋白质的认识 图源:deepmind.com
目前,研究者能够利用AlphaFold2的蛋白数据库,加速核孔复合物的蛋白质结构的探索,同时推进被忽视疾病的药物研发,以期揭秘和预防帕金森病这种令人头疼的神经衰退性疾病。
除了AlphaFold2,华盛顿大学戴维·贝克(David Baker)教授开发的RoseTTAFold,也给蛋白质研究带来了新的视角。这一系统将AI训练得可以根据预定的蛋白质目标或已知的蛋白质功能位点,来 “构想” 和设计蛋白质结构——就像你在手机上输入几个字母后,输入法会自动给你补全整个单词。
RoseTTAFold系统突破了AlphaFold2的一个重要局限:不仅可用于预测单一蛋白质的结构,还可以用于预测蛋白复合体的构象。

2021年7月,RoseTTAFold系统登上Science杂志封面,图源:uw.edu
人工智能的加入无疑给蛋白质研究领域带来了新的思路。不管是AlphaFold2,还是RoseTTAFold,抑或是未来将会出现的新的应用系统,都打开了蛋白质研究领域的新天地。
但要想真的触及 “未充分研究蛋白质” 的真面目,只预测出结构,知道它 “长什么样” 恐怕还不够。
♦ 探索蛋白质宇宙中的暗物质
当我们准确知道一个蛋白质长什么样、是怎么折叠的、每个部分的氨基酸序列是什么之后,要想知道它具体的功能,还要进行一系列的比对和分析,这个过程需要耗费大量的人力和时间。
去年夏天,AlphaFold2已预测出超过100万个物种的2.14亿个蛋白质结构,几乎涵盖了DNA数据库中已知生物的所有蛋白质。第一只靴子得以落地,另一只在哪儿?更难的问题仍然存在——知道蛋白质长啥样还不够,更重要的是研究它的功能。
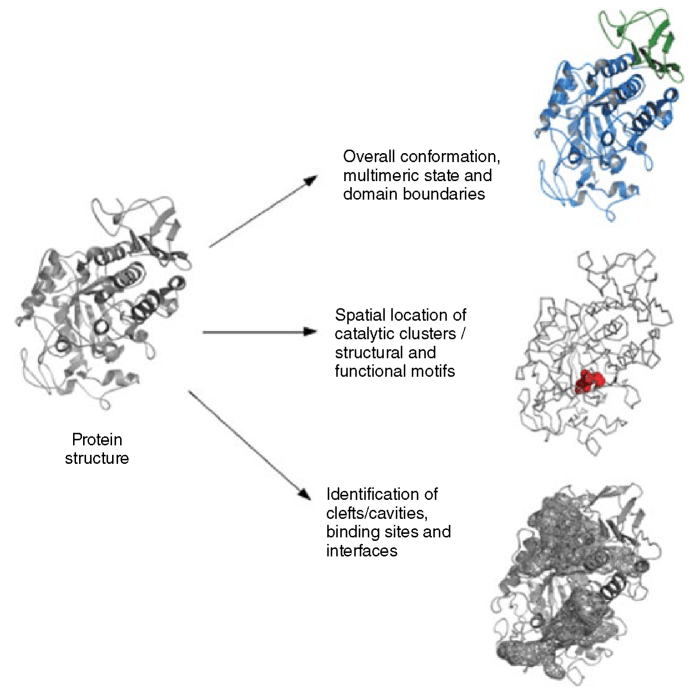
从蛋白质的结构到功能 图源:ebrary.net
关于蛋白质世界的探索,西湖大学终身副教授、西湖实验室iMarker lab主任、西湖欧米创始人郭天南认为,“如果把整个蛋白质领域比作宇宙,那么,未充分研究的蛋白质就是宇宙中的暗物质。要研究这些暗物质,就必须搞清楚结构和功能两个层面。以前我们没办法,AlphaFold2的出现,相当于打开了我们研究这种暗物质的切口。而AI赋能的蛋白质谱则为研究这些暗物质的功能提供了有效的工具。”
有了切口,下一步就需要质谱在蛋白质功能上发挥作用了。蛋白质质谱法(Protein mass spectrometry)是将质谱仪用于研究蛋白质的技术,是准确测定和表征蛋白质质量数的重要方法。目前,科学家已经开发了多种方法和仪器,用于不同的用途。

质谱的蛋白质鉴定过程
基于质谱的蛋白质鉴定过程,通常需要将蛋白质酶解成肽,然后将其分离、片段化、电离并通过质谱仪捕获,根据质谱峰来鉴定和定量蛋白质。但从串联质谱中准确鉴定蛋白质的功能是一项非常具有挑战性的任务。
在这个过程中,人工对比这一步是非常 “烧脑” 并且耗时的,这也是为什么蛋白质领域的研究存在 “街灯效应”——那些越是被研究得透彻的蛋白质,研究的人越多,而那些未充分研究蛋白质常常无人问津。这也是 “未充分研究蛋白质” 计划被设立的主要原因。
研究者于是提出一个 “天马行空” 的想法:在现有的蛋白质组数据库的基础上,结合人工智能,打造一款智能引擎帮助人们鉴定未知的蛋白质的功能。
海量预测蛋白质结构,得益于 “数据+AI” 的强强联手模式。
对于蛋白质功能的研究来说,蛋白质组表达功能的数据库已经在科学发展的过程中逐步形成了,接下来就是怎么联手AI——而这也只是时间问题。
正如目前大火的人工智能聊天机器人ChatGPT,它能在海量的话题中实现复杂的交互,得益于其依托海量文本大数据的智能模型训练。在蛋白质研究领域,我们期望在蛋白质定性过程中,也打造出一款AI软件,训练、优化它,并吸纳现有的蛋白质组数据库,让它能将所有的蛋白质序列与其功能串联起来,快速为一个未知的蛋白质定性。
如果这个目标得以实现,那么蛋白质功能的鉴定难题可能会有质的飞跃,而蛋白质宇宙的暗物质也将被AI “照亮”。
总之,蛋白质世界探索下一步的目标是,将AI用于分析我们已知的蛋白质组表达功能的大数据,成为下一代的蛋白质智能引擎。这样的 “强强联合”,不仅会带我们走进全新的生物学世界,还会很大程度地推进新靶点、新药物的研发,真正实现蛋白质宇宙的 “暗物质” 的探索。